[컴퓨터 구조] Pipelining
파이프 라인으로 인해 줄일 수 있는 시간은 가장 긴 pipeline state의 영향을 받는다.
Pipeline state의 개수가 많아질수록 속도가 빨라질 수 있다.
Pipeline state의 시간의 언벨런스 하면 속도가 느려진다.
1. Instruction fetch(IF)
- 메모리에서 instruction을 불러와서 instruction register에 저장, pc+4
- IR을 다음 state 전까지 가지고 있음(한 싸이클마다 state가 바뀜)
2. Instruction Decode/Register Fetch Cycle(ID)
- Instruction을 디코딩하고 register value를 읽어옴
- 16비트를 확장
- 다음 state 전까지 가지고 기다림
3. ALU Execution(EX)
- 연산 수행 또는 주소 계산
4. Memory Access(MEM)
- ALU 쓸때는 아무것도 안하고 load나 store일 때는 메모리에 접근
5. Write Back(WB)
- ALU를 하거나 data load를 해서 write register에 저장
- Pipeline이라 write register이 덮어써질 수 있음 -> 각 state마다 저장해놓는 레지스터 추가

<pipeline issue>
- Pipeline stage를 밸런스 있게
- Keeping pipeline correct, moving, and full in presence of events that disrupt pipeline flow
- Pipeline advance
<Pipeline harzard>
1. Structure hazard
ex) 여러 명령어가 같은 H/W 리소스를 사용
2. Data hazard
ex) 그 전 명령어에서 레지스터에 담긴 데이터 값을 바꿔서 다음 명령어에서 제대로 된 값을 못 불러옴
3. Control hazard
ex) 그 전 명령어에서 pc를 바꾸기 전에 그 다음 명령어가 실행됨
- Stall을 넣어줌 -> CPI 올라가서 효율이 안나옴
- Bubbles을 넣어 이러한 문제를 없애줌 -> 오히려 비효율적
<Stall 발생 이유>
- 명령어간 동일한 리소스를 사용할 때
- Data, control dependences
- 한 state에서 Cycle을 여러 개 쓰는 작업일 때
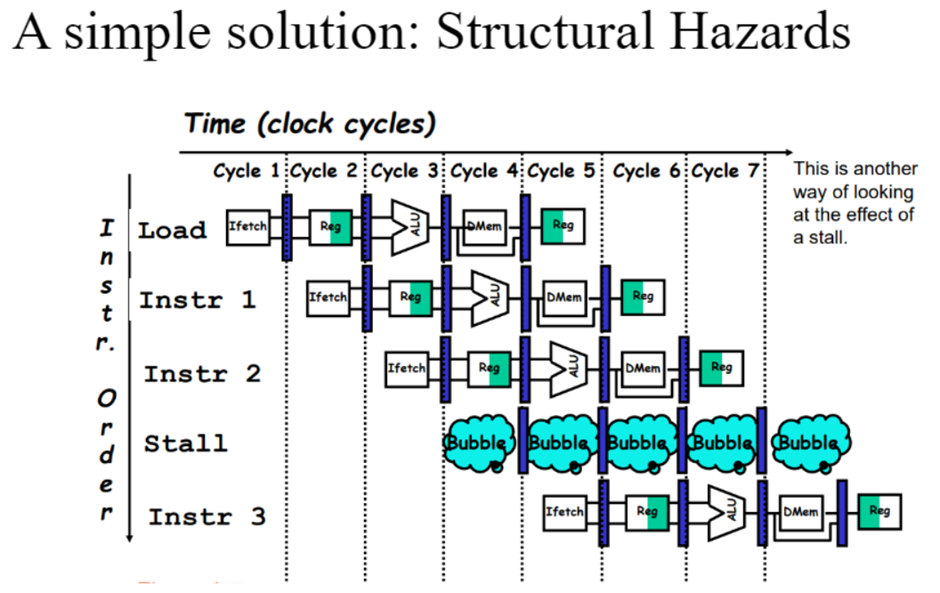
DMem과 Ifetch가 같은 하드웨어를 사용하기 때문에 structural hazard 발생 (Harvard architecture에서는 instruction memory와 data memory가 따로 있지만 전달 포트가 제한적이면 structural hazard가 발생할 수 있다.)
<Dealing with structural harzards>
1. Stall – 장점: 단순하고 비용 낮음, 단점: CPI 증가
2. Pipeline hardware resource – multi cycle resource
3. Replicate resource – 하드웨어를 더 둠, 장점: stall 안해도 됨, 단점: 비용 증
<Dealing with data dependences>
1. Stall – 장점: 간단, 저렴, 단점: 퍼포먼스 떨어짐
2. Forward(Bypass/Shortcircuit): 사전에 data가 write 되기 전에 계산만 된 상태에서 path를 만들어 다음 명령어에 전달되어 사용될 수 있게 함


lw의 경우에는 DMem에 접근해야만 레지스터 값을 가져올 수 있으므로 다음 명령어에게 레지스터 값을 미처 전달하지 못하는 상황이 발생할 수 있음 -> 어쩔 수 없이 stall

3. Pipeline scheduling – 컴파일러가 instruction 순서를 바꿔서 stall을 줄임

<Control hazard>
- brench 명령어에서 발생
- 해결법
1. Stall until branch direction is clear
목표 주소가 정해질 때까지 stall
2. Predict branch not taken
일단 not taken으로 가정하고 진행하다가 taken이면 진행하던거 날리고 맞으면 계속 진행
3. Predict branch taken
taken으로 가정하고 진행 but 목표 주소를 정할 때까지 stall 해야함
4. Execute both paths
둘 다 가정하고 진행 but 비용 많이 듬
5. Delayed branch
Branch 전 명령어들이 branch랑 관련이 없다면 branch를 미리 실행시켜 놈


<Pipeline hazard 요약>
- Structural hazard 해결법: 하드웨어 리소스를 늘린다
- Data hazard 해결법: forwarding, compiler scheduling
- Control hazard 해결법: taken인지 not taken인지 잘 맞추고 어디로 이동할지 잘 예측
- 파이프라인의 성능은 파이프라인을 잘게 쪼갤수록 높아짐, 하지만 hazard issue는 더 커질 수 있음

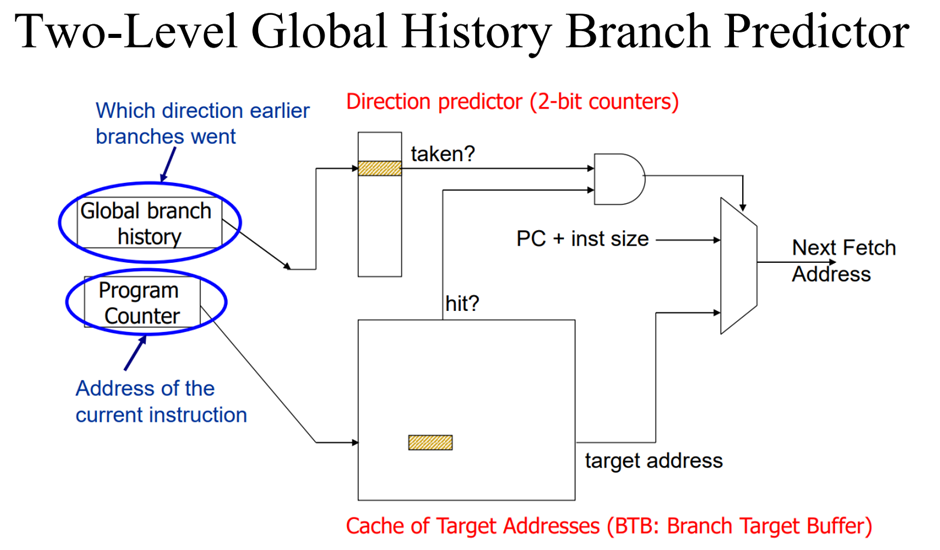
<Branch prediction>
- Fetch stage에서 세가지를 예측해야 한다.
1. Fetch된 명령어가 branch인지
2. Branch가 taken인지 not taken인지
3. Branch의 target address가 어딘지
이전에 branch가 taken이어서 target address로 갔다면 다음에 taken 됐을 때도 그곳으로 감 -> Branch Target Buffer(BTB)라는 저장소를 만들어서 target address를 저장

- BTB를 통해 현 명령어가 branch인지 아닌지도 알 수 있음(target address가 저장되어 있으면 branch)
- 정적 예측과 동적 예측이 있음
- 정적 예측: always not taken, always taken, BTFN, profile based, program analysis based
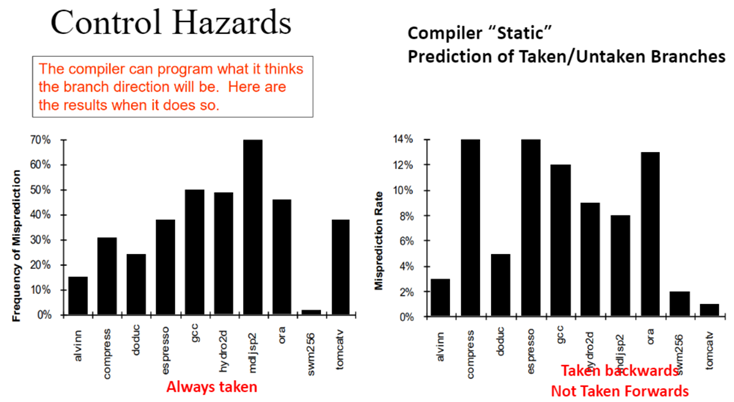
- BTFN: Backward branch는 taken으로, forward branch는 not taken으로 예측(backward는 반복문일 확률이 높고 반복문이면 taken될 확률이 높기 때문에)
- Profile-based prediction: branch의 행동을 기록하고 그것을 바탕으로 예측
- 동적 예측: Last time prediction, Two-bit counter based prediction, Two-level prediction
<Last time prediction>
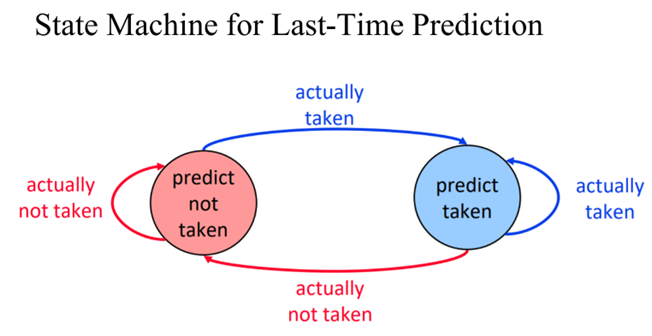
예측이 틀리면 다음 예측을 바꿈
어떤 위치의 branch의 마지막 값으로 다음에 다시 그 위치에 왔을 때 branch를 예측
반복되는 패턴이 있을 때는 좋으나 taken과 not taken이 번갈아 가면서 나올 때는 효율 떨어짐
<Two bit counter based prediction>

예측이 두번 틀리면 다음 예측을 바꿈
<Two level prediction>

- Global branch correlation: Branch의 outcome이 주변 branch들의 outcome에 영향을 받는다.

- Local branch correlation: branch의 outcome이 반복된다.
- Implementation

Global History Register: branch들의 taken, not taken 정보를 가지고 있는 레지스터
Pattern History table: taken, not taken 정보를 가지고 어떻게 예측할 것인지 담고 있는 테이블
GHR 정보를 바탕으로 PHT에 접근, PHT에 저장되어 있는 예측 값(00, 01, 10, 11)으로 예측, 예측과 다르면 PHT를 업데이트