신뢰도 높은 리뷰 탐색 프로젝트(파이어베이스, 파이썬)
인터넷에서 내가 찾고자 하는 리뷰를 검색해보면 신뢰할만한 리뷰를 찾을 때도 있지만 멋모르고 광고성 리뷰를 읽게 되는 경우도 적지 않다. 때문에 이번에는 파이썬과 파이어베이스를 이용해 리뷰에 적힌 단어들 중 광고성 리뷰에서 나올법한 단어들이 있는지를 확인하고 이를 바탕으로 그 리뷰의 신뢰도를 판단해주는 파이썬 프로젝트를 진행해봤다.
전체 코드는 다음과 같다.
# import : firebase db
import firebase_admin
from firebase_admin import credentials
from firebase_admin import db
# import : crowling
import urllib.request
import urllib.parse
from bs4 import BeautifulSoup
import warnings
# import : make random key
import random
import string
# db
cred = credentials.Certificate("crowlingtest-firebase-adminsdk-566vk-c23534af09.json")
firebase_admin.initialize_app(cred, {"databaseURL": "https://crowlingtest.firebaseio.com/"})
# crowling
currPage = 1
endPage = 1
countContents = 0
goto = 1 # 1 : true, 0 : false
while True:
goto = 1
dir = db.reference("검색어")
keyword = dir.get()
keyword = keyword.replace('"','')
print(keyword)
if(keyword == "종료"):
break
baseUrl = "https://search.naver.com/search.naver?query="
plusUrl = keyword
while currPage == endPage:
url = baseUrl + urllib.parse.quote_plus(plusUrl) + "&sm=tab_pge&srchby=all&st=sim&where=post&start=" + str(currPage)
html = urllib.request.urlopen(url).read()
soupSearch = BeautifulSoup(html, "html.parser")
contents = soupSearch.find_all('a', {"class": "api_txt_lines total_tit"})
dir = db.reference(plusUrl) # 검색어 하위에 데이터베이스 생성
for i in contents:
if (countContents >= 10 or goto == 0):
break
# init "value"
save_title = i.text # 블로그 제목 > get title
save_url = i.attrs['href'] # 블로그 url > get url
blogBody = "" # 블로그 본문
score = 0 # 광고성 점수
agree = 0
disagree = 0
# 본문
warnings.filterwarnings("ignore", category=UserWarning, module='bs4')
blogUrl = urllib.request.urlopen(save_url).read()
soupBlog = BeautifulSoup(blogUrl, "html.parser")
body = soupBlog.select("#mainFrame")
if "blog.naver.com" in save_url:
if len(body) > 0:
contentUrl = urllib.request.urlopen("https://blog.naver.com" + body[0]['src']).read()
soupContent = BeautifulSoup(contentUrl, "html.parser")
components = soupContent.select(".se-main-container .se-component")
for component in components:
blogBody += component.text.strip("\n")
# check 광고성 여부
bad = ['경제적', '소정', '제공', '협찬', '유료', '대가성', "지원", "원고료", "업체", "제공받아", "식사권", "광고주", "해당업체", "무상", "작성되었습니다"]
good = ["내돈내산", "결제", "솔직후기", "영수증", "찐후기", "실제리뷰"]
reverse = ["없", "않"]
for badWord in bad:
if badWord in blogBody:
score -= 1
for goodWord in good:
if goodWord in blogBody:
score += 1
for badWord in bad:
for reverseWord in reverse:
if badWord + ' ' + reverseWord in blogBody:
score += 2
elif badWord + reverseWord in blogBody:
score += 2
for goodWord in good:
for reverseWord in reverse:
if goodWord + ' ' + reverseWord in blogBody:
score -= 2
elif goodWord + reverseWord in blogBody:
score -= 2
# for check
print(save_title)
print(save_url)
# blog 글 일때만 db에 update
if blogBody:
urlKey = ''.join(e for e in save_url if e.isalnum())
urlKey = urlKey.replace("httpsblognavercom","")
overlap = 0
try:
for i in dir.get():
if i == urlKey:
overlap = 1
except:
overlap = 0
if (overlap == 0):
dir.update({urlKey : [save_title, save_url, blogBody, score, agree, disagree, [""], [""]]})
dir = db.reference("검색어")
new_keyword = dir.get()
new_keyword = new_keyword.replace('"','')
if (keyword != new_keyword):
goto = 0
dir = db.reference(plusUrl)
# go to the next page
countContents += 1
countContents = 0
currPage += 1
currPage = 1
dir = db.reference("검색어")
if (goto == 1):
print("새로운 검색어를 기다리고 있습니다.....")
while True:
new_keyword = dir.get()
new_keyword = new_keyword.replace('"','')
if(keyword != new_keyword):
print("검색어가 변경되었습니다.")
break
else:
print("검색어가 변경되었습니다.")
전체 코드를 모두 다 설명하기보다 기능 위주로 설명을 하도록 하겠다.
일단 이번 프로젝트에서는 파이썬과 파이어베이스를 사용했다. 이 코드만 보자면 파이어베이스를 사용할 이유가 전혀 없으므로 이에 대해 의문을 가질 수도 있다. 그 이유는 이 프로젝트가 파이썬으로 크롤링해 가져온 리뷰의 신뢰도 점수를 메기는 것 뿐만 아니라 크롤링한 리뷰와 신뢰도 점수를 파이어베이스에 저장한 뒤 이 데이터들을 바탕으로 안드로이드 스튜디오를 이용한 앱을 만드는 것까지가 완성이기 때문이다. 그렇지만 여기에는 파이썬으로 작성한 코드만을 적어놓았다.

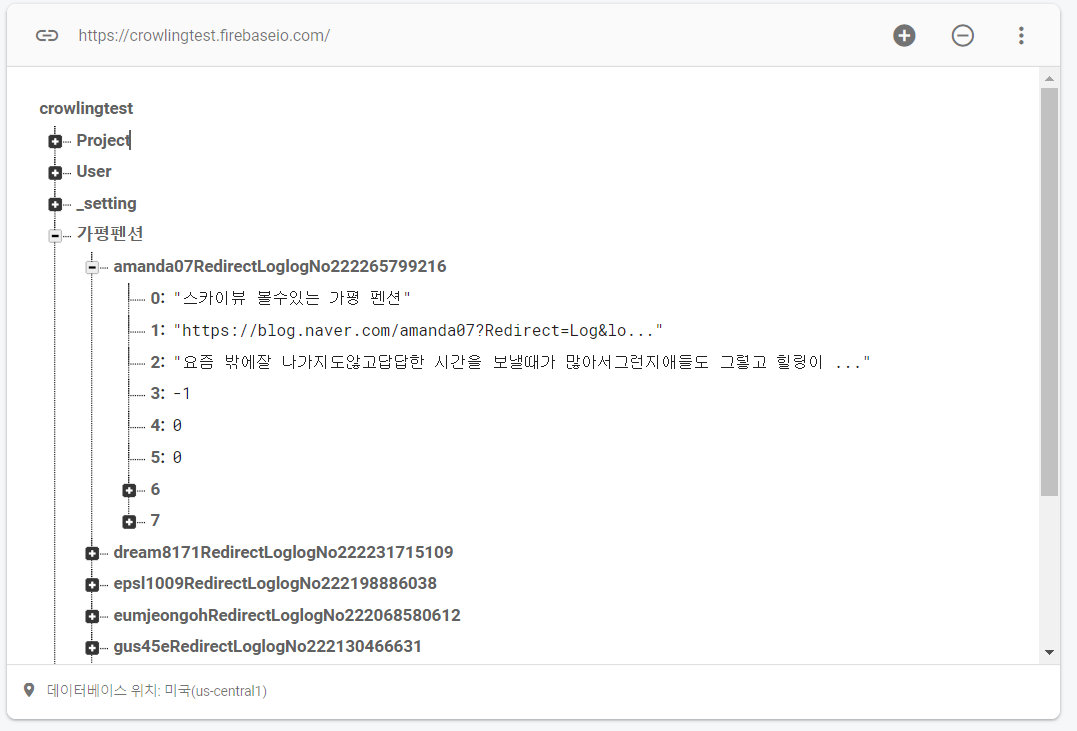
신뢰도 점수의 경우에는 '제공', '협찬', '광고주' 등의 '부정적'단어가 발견될때마다 점수를 1점씩 차감하고 '내돈내산', '솔직후기', '찐후기' 등의 '긍정적'단어가 발견될때마다 점수를 1점씩 올려주었다. 그리고 '없', '않'과 같이 단어 앞에 붙으면 단어의 뜻이 180도 바뀌는 어간도 고려해주었다.
또한 while문을 사용하여 파이어베이스에 저장되어있는 검색어가 변경될 시에 이를 감지하고 새로 갱신된 검색어에 대한 리뷰를 찾아주는 기능도 추가해주었다.

아직 신뢰도 점수를 매기는데에 있어서 객관성과 근거가 조금 부족한 감이 있기 때문에 이 부분을 더 보완해나갈 예정이다.