
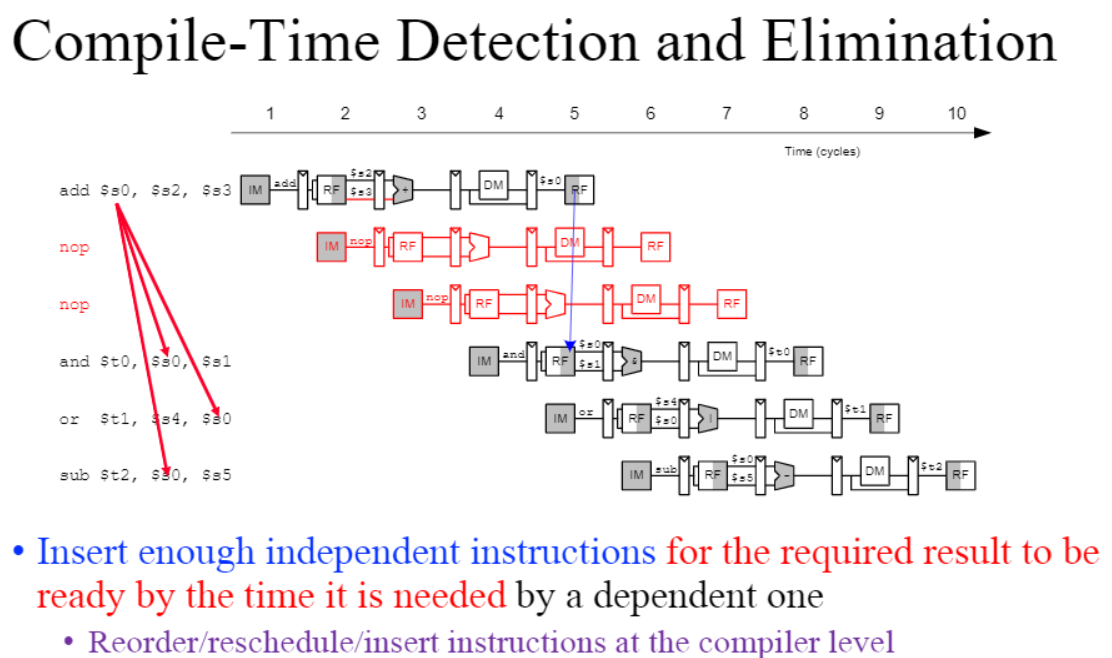
<Compile-time Detection and Elimination>
컴파일 과정에서부터 data dependeces을 감지하고 nop을 넣어 depenceces를 제거하는 것
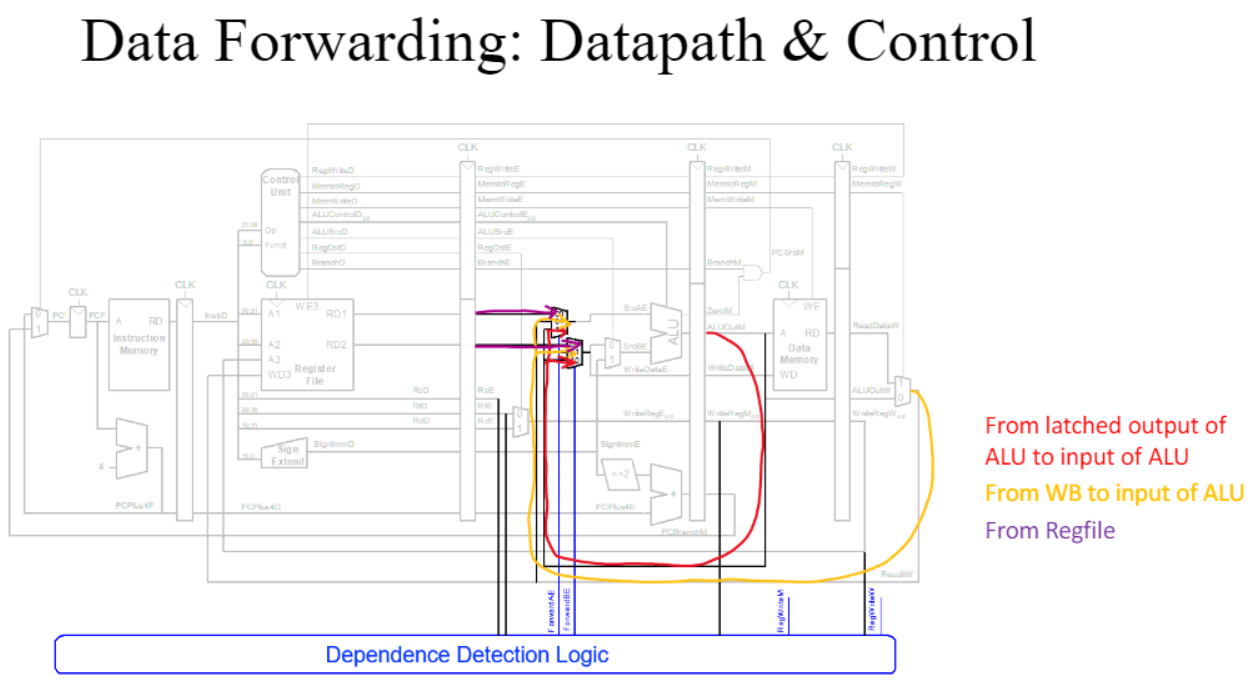
<Data Forwarding>
data를 write하기 이전에 미리 그 값을 다음 명령어로 전달해주는 방식

다음 명령어로 data를 전달해줄 수 있는 line 만들어 data dependences를 줄인다. 하지만 모든 경우에 적용될 수 있는 것은 아니고 어쩔 수 없이 stall 해줘야 하는 상황이 있을 수 있다. ex) lw 다음에 and 명령어가 올 때 등
<Early Branch Resolution>
그 이전에 하드웨어를 추가로 둬서 branch가 taken인지 not taken인지, taken이라면 어디로 가야하는지를 ALU 이전에 계산하는 방식
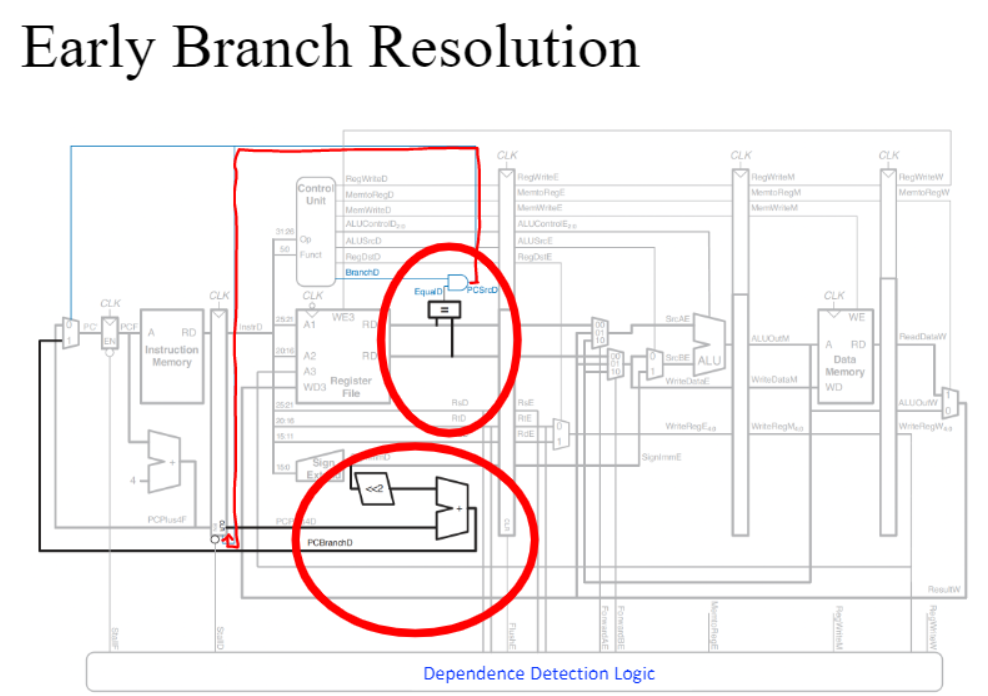
장점
- branch를 잘못 예측했을 때의 패널티를 줄일 수 있다 -> CPI가 줄어듬
단점
- clock cycle time이 늘어날 수 있음(clock cycle time은 가장 시간이 오래걸리는 stage의 영향을 받기 때문에 하드웨어를 추가함으로써 그 stage의 시간이 다른 stage의 시간보다 월등히 커진다면 전체 clock cycle time이 늘어날 수 있다.)
- 추가적 하드웨어에 대한 비용 발생
<Predicted Execution>
branch를 없애자 -> condition에 따른 두가지 명령어를 둘다 계산만 해놓고 condition에 맞는 한가지만 실제로 commit 시키자
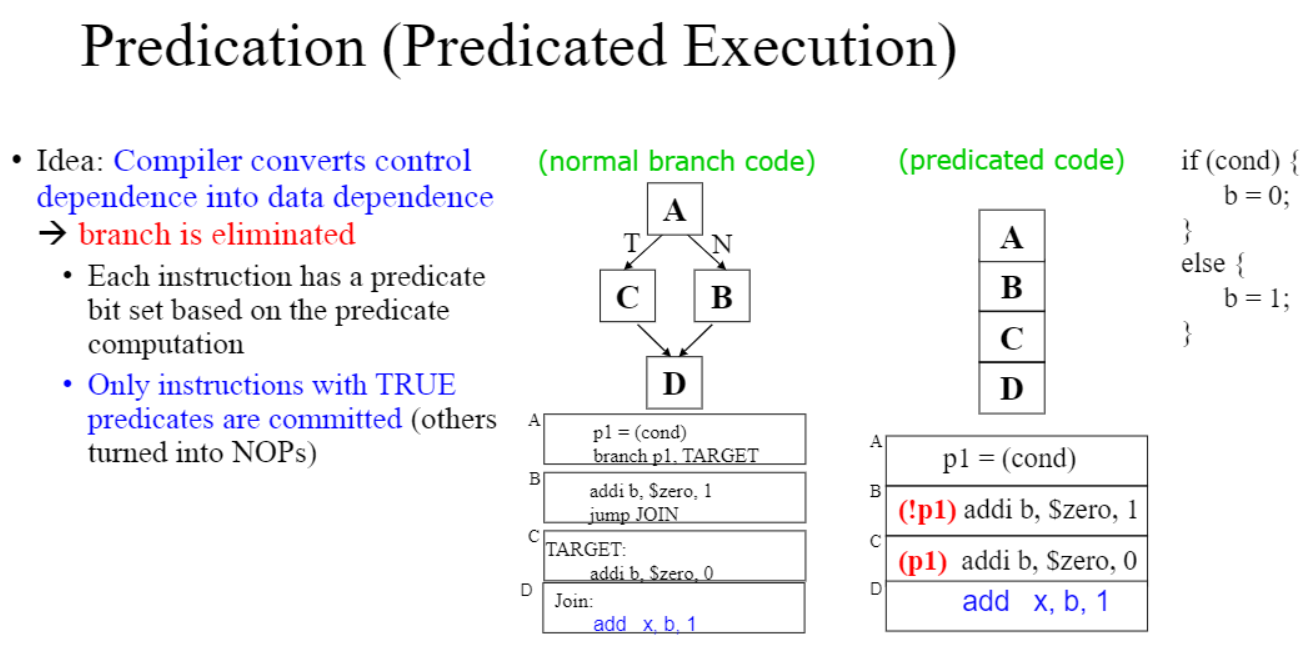
둘 다 실행시키다가 올바른 예측에 대한 쪽만 적용한다.

장점
- misprediction cost가 없어진다.
- code optimize가 더 좋아진다.
단점
- 불필요한 작업을 해야 함(일단 둘다 실행해야 함)
- 추가적 ISA나 하드웨어의 지원이 필요
<Loop Unrolling>
Loop 코드에서 branch를 줄이는 것

일반 for문에서 내부 코드의 길이를 늘려 branch를 최대한 줄일 수 있다.
장점
- 프로그램 효율이 증가한다
- loop 오버헤드를 줄일 수 있다
단점
- 프로그램 코드 크기가 커진다.
- dependences issue가 발생할 수 있다.
<Superpipelining and Superscalar>
- Superpipelinging: pipeline state를 더 쪼개서 clock rate를 더 증가시키는 방식
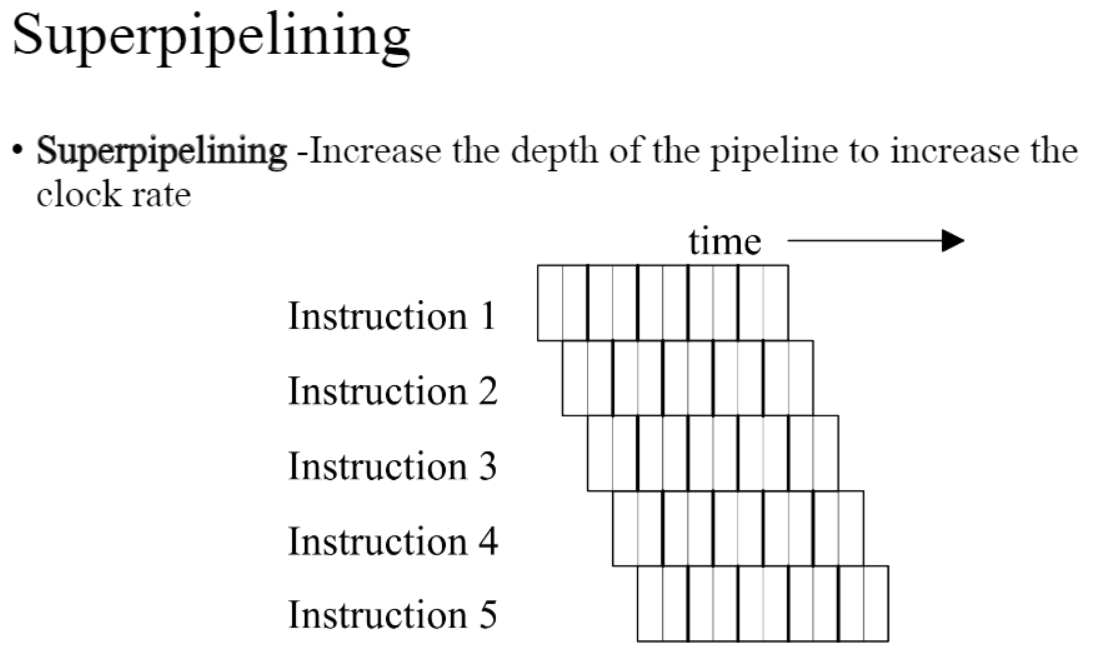
- Superscalar: 한번에 fetch하는 명령어를 더 늘리는 방식

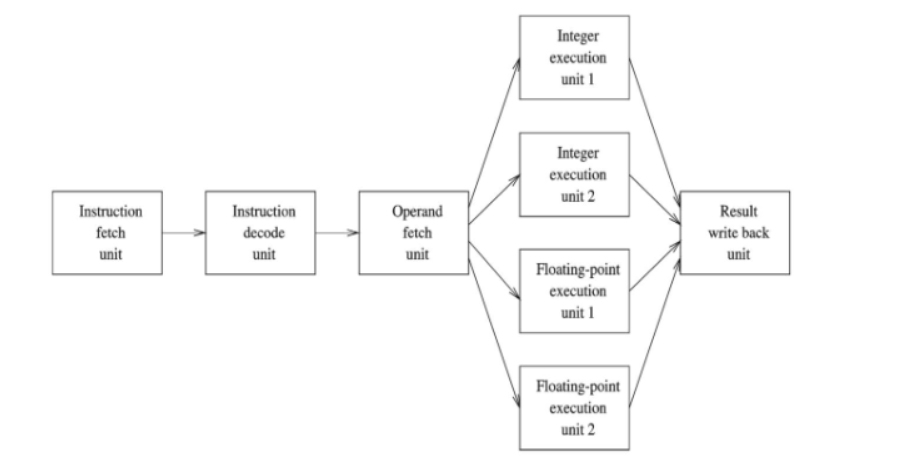
<VLIW>
very long instruction word architecture으로 컴파일러가 서로 독립적인 명령어들을 찾고 이를 하나의 VLIW 명령어로 묶어준다.


장점
- 소프트웨어에서 알아서 묶어주니 하드웨어는 단순해도 됨
단점
- 컴파일러가 매 사이클마다 N개의 독립적인 명령어들을 찾아야한다 (없다면 VLIW에 nop을 넣어야 한다)
- 한번에 실행시킬 명령어 개수를 변경하려면 컴파일을 다시 해줘야 함
- stall 될 때도 여러 개씩 stall 해야 함
.
<Superscalar>
VLIW가 어떤 instruction을 동시에 처리할지 컴파일러가 정적으로 결정한다면 superscalar는 어떤 instruction을 동시에 처리할지 하드웨어에서 동적으로 결정한다.
superscalar에는 순서대로 실행하는 in-order 방식과 순서를 변경해 실행하는 out-of-order 방식이 있다.
in-order 방식의 경우 필연적으로 여러가지 dependency issue들이 발생할 수 밖에 없다.

이 때문에 서로 의존성이 없는 독립적인 instruction끼리 묶어서 실행하는 out-of-order 방식이 존재한다.
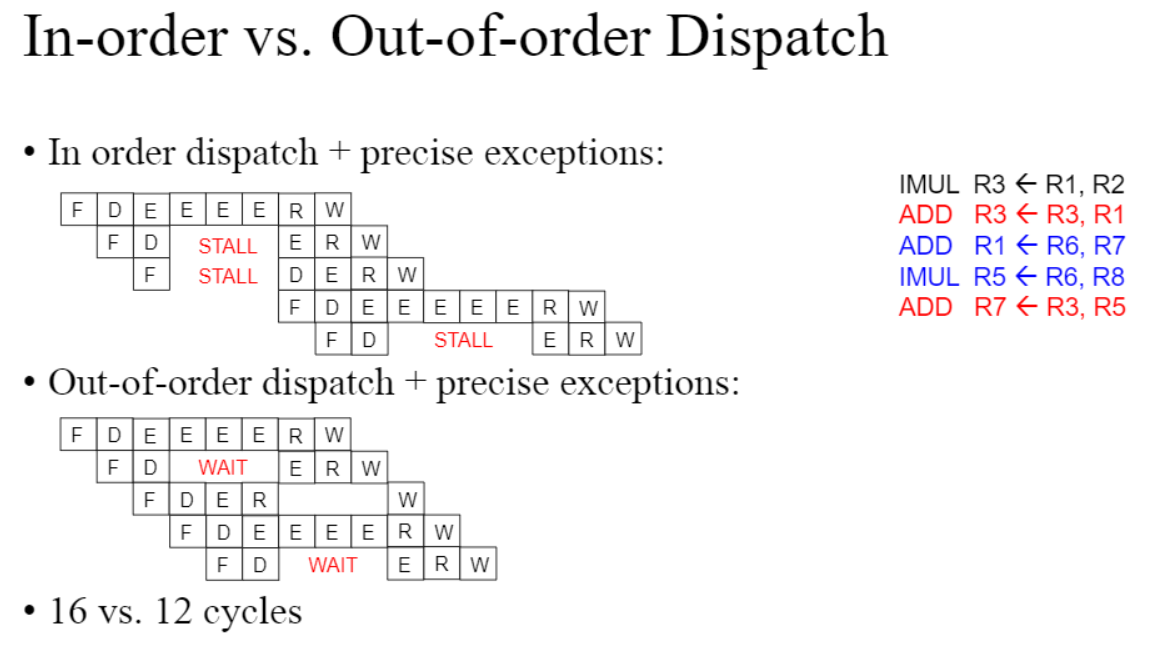
out-of-order 방식을 사용하면 앞선 명령어가 dependency issue로 인해 잠시 실행이 중단됐을 때 다른 명령어를 실행시켜 clock cycle을 줄일 수 있다.
그렇다면 out-of-order 방식에서 순서를 어느 정도까지 바꾸는 것을 허용해야 할까? 우선 명령어를 처리하는 세가지 단계를 살펴보자.

1. Instruction issue
ALU에 명령어가 들어가서 execution이 시작하는 단계
2. Instruction completion
ALU에서 연산이 끝나는 단계
3. Instruction commit
연산이 끝난 후 연산 결과를 레지스터 파일이나 데이터 주소에 써주는 단계
- In order issue with In order completion(IOI-IOC)
말 그대로 ALU에 순서대로 명령어가 들어갔다가 순서대로 execution이 끝나는 방식
아래 그림은 pipeline stage가 3개이고 2개의 명령어씩 실행시키는 프로세서의 예시이다.

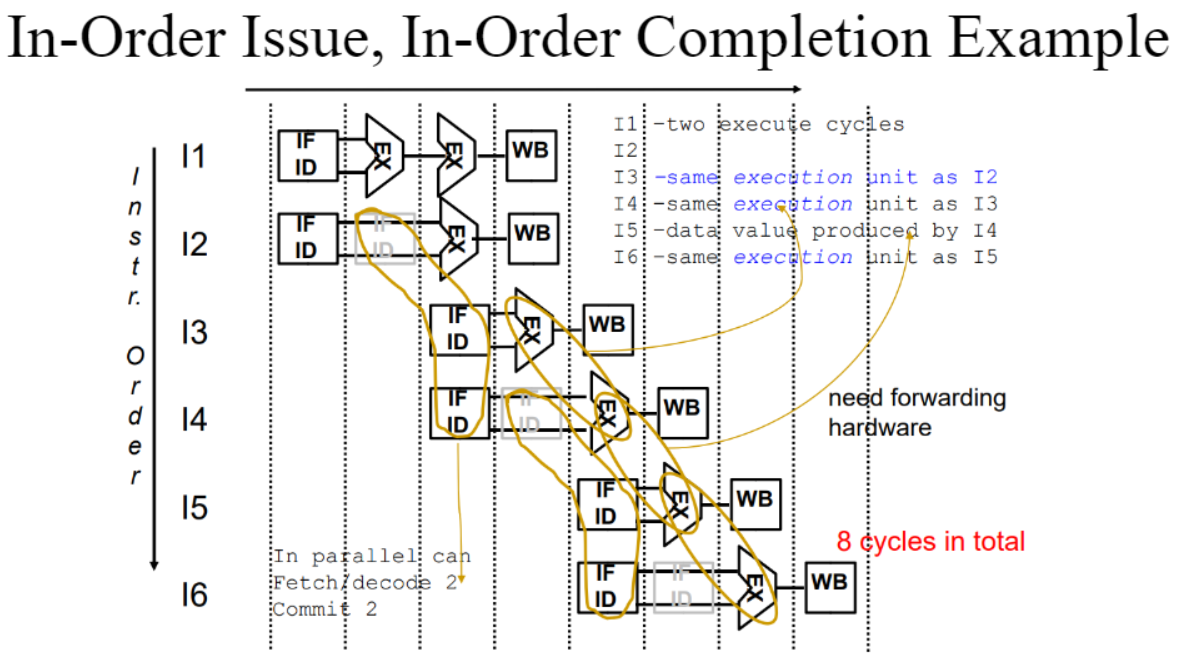
execution이 순서대로 실행되고 순서대로 끝나야하기 때문에 비효율적이다.
- In-order issue with Out-of-order completion(IOI-OOC)
ALU에 순서대로 들어가지만 연산은 순서대로 끝날 필요 없는 방식
아래는 전 예시를 IOI-OOC 방식으로 수행한 것이다.
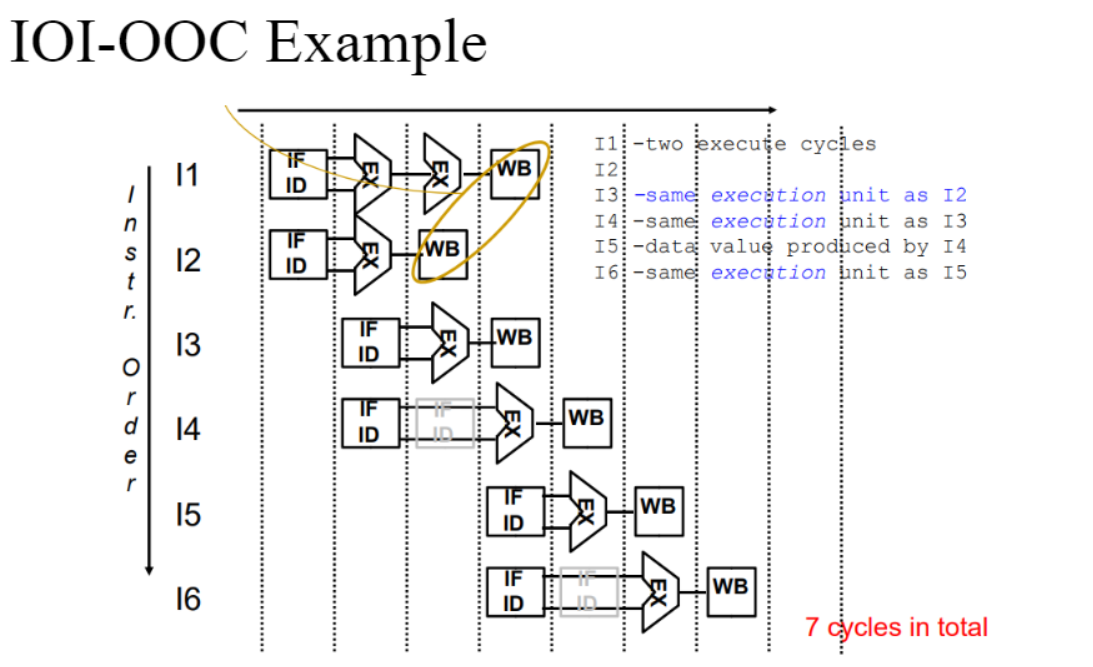
굳이 순서대로 끝날 필요가 없기 때문에 비교적 더 효율적으로 바뀌었다.
- Out of order issue with Out of order completion(OOI-OOC)
ALU에 명령어가 들어가고 끝나는 순서가 모두 상관없는 방식
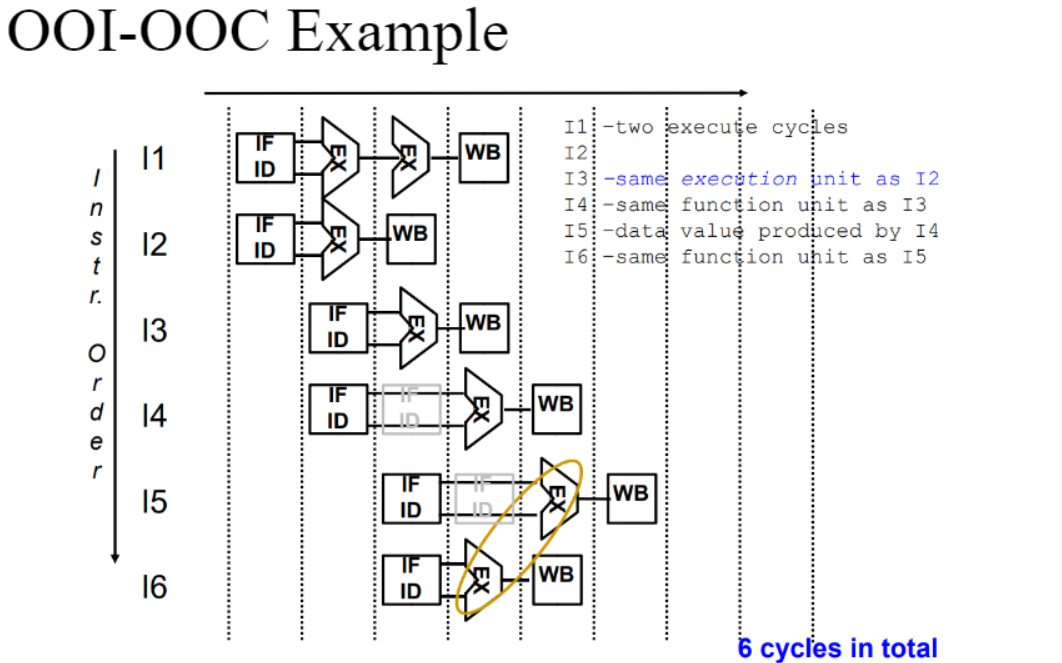
I5와 I4에 data dependecy가 있기 때문에 I6를 먼저 execution 해주어 clock cycle을 줄였다.
장점
- IPC가 높아진다.
단점
- dependency를 체크해줄 수 있는 로직이 필요하다.
'학교공부 > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터 구조] Memory Hierarchy (0) | 2023.06.03 |
|---|---|
| [컴퓨터 구조] Multithreading (0) | 2023.06.03 |
| [컴퓨터 구조] Pipelining (0) | 2023.04.25 |
| [컴퓨터 구조] ISA (0) | 2023.04.24 |
| [컴퓨터 구조] Computer Organization/Performance (0) | 2023.04.24 |