
KNN(K-Nearest Neighbor) 알고리즘을 이용해 종양 덩어리에 대한 데이터가 주어졌을 때 이 종양 덩어리가 단순히 양성종양인지 아니면 악성종양인지 판별해주는 머신러닝 모델을 만들어보았다.
개발환경은 구글의 Colab에서 진행하였으며 다음은 전체 코드이다.
https://github.com/hizibu7/datascience_practice/blob/master/cancer_%20discrimination
GitHub - hizibu7/datascience_practice
Contribute to hizibu7/datascience_practice development by creating an account on GitHub.
github.com
K-최근접 이웃 회귀 알고리즘이란?
우선 코드를 살펴보기에 앞서 여기서 사용된 KNN 알고리즘에 대해 간단하게 살펴보자.
KNN 알고리즘은 어떤 데이터에 대한 답을 얻을 때 주변의 다른 데이터들에서 다수를 차지하는 것을 정답으로 갖는 알고리즘이다.
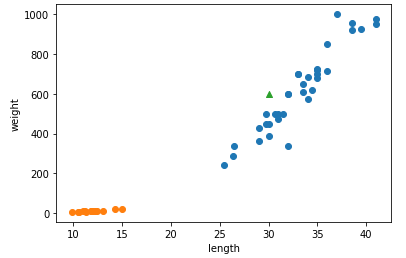
예를 들면 위 그림에서 파란 점이 A, 주황 점이 B라고 할 때 삼각형으로 표시된 데이터는 A일 확률이 높다고 말할 수 있을 것이다. 왜냐하면 삼각형 주변에 A가 더 많기 때문이다.
이렇듯 KNN 알고리즘은 단순하면서도 효율적이라는 장점이 있는 한편, 각 데이터 간의 거리를 일일이 계산해야 하기 때문에 높은 컴퓨팅 파워를 요구하며 시간이 비교적 오래 걸린다는 단점 또한 존재한다.
데이터 가공하기
'Kaggle'이라는 사이트에서 각자 30개의 특성을 가진 종양 데이터 569개를 가져왔다.
https://www.kaggle.com/buddhiniw/breast-cancer-prediction/data
Breast cancer prediction
Explore and run machine learning code with Kaggle Notebooks | Using data from Breast Cancer Wisconsin (Diagnostic) Data Set
www.kaggle.com
import io
import pandas as pd
data = pd.read_csv(io.BytesIO(myfile['data.csv']))
diagnosis = data['diagnosis']
radius_mean = data['radius_mean']
M_radius_mean = []
B_radius_mean = []
print(diagnosis)
print(radius_mean)
n = 0
count_M = 0
count_B = 0
for i in diagnosis:
if i=='M':
count_M+=1
M_radius_mean.append(radius_mean[n])
else:
count_B+=1
B_radius_mean.append(radius_mean[n])
n+=1
print(count_M)
print(count_B)
print(M_radius_mean)
print(B_radius_mean)
이후 위와 같은 방식으로 데이터가 악성인지 양성인지에 따라 분류한 결과 양성종양 데이터가 357개, 악성종양 데이터가 212개임을 확인할 수 있었고 본 코드에서와 같이 30개의 특성값을 양성인지 악성인지에 따라 나누어 가공된 데이터를 얻었다. (이때 M_radius_mean과 B_radius_mean에서 M은 악성, B는 양성이라는 뜻이다.)
지도학습
지도학습에서는 데이터와 그에 대한 정답을 입력과 타깃이라 하고 이를 훈련 데이터라 부른다.
#입력과 타깃
cancer_data = [[a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z,aa,ab,ac,ad] for a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z,aa,ab,ac,ad in zip(radius_mean, texture_mean, perimeter_mean, area_mean, smoothness_mean, compactness_mean, concavity_mean,
concave_points_mean, symmetry_mean, fractal_dimension_mean, radius_se, texture_se, perimeter_se, area_se, smoothness_se, compactness_se, concavity_se, concave_points_se, symmetry_se, fractal_dimension_se, radius_worst, texture_worst, perimeter_worst,
area_worst, smoothness_worst, compactness_worst, concavity_worst, concave_points_worst, symmetry_worst, fractal_dimension_worst)]
cancer_target = [1]*212 + [0]*357
따라서 여기서의 입력은 가공해 놓은 데이터가 될 것이고 타깃은 그 데이터가 양성(0) 값을 갖는지 악성(1) 값을 갖는지에 대한 여부를 리스트로 표현한 형태가 될 것이다.
지도학습 알고리즘은 그 이름에서도 알 수 있듯이 데이터를 통해 훈련을 시켜야 하고, 그 후에는 그 모델이 좋은 모델인가를 판단하기 위해 데이터를 사용해 평가해야만 한다. 이 때문에 훈련을 시키기 위한 훈련 세트(훈련 데이터)와 평가를 하기 위한 테스트 세트(테스트 데이터)가 필요하다. 이때 훈련 세트와 테스트 세트는 각각 달라야 하고 이 둘을 마련하기 위한 방법의 하나는 전체 데이터를 훈련 세트와 테스트 세트로 나누는 것이다.
#훈련 세트와 테스트 세트 만들기
'''
input_arr = np.array(cancer_data)
target_arr = np.array(cancer_target)
np.random.seed(500)
index = np.arange(569)
np.random.shuffle(index)
train_input = input_arr[index[:500]]
train_target = target_arr[index[:500]]
test_input = input_arr[index[500:]]
test_target = target_arr[index[500:]]
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
train_scaled = (train_input - mean) / std
test_scaled = (test_input - mean) / std
'''
train_input, test_input, train_target, test_target = train_test_split(cancer_data, cancer_target, random_state=500)
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
train_scaled = (train_input - mean) / std
test_scaled = (test_input - mean) / std
훈련 세트와 테스트 세트를 얻기 위해 sklearn의 train_test_split(입력, 타겟을 넣어주면 자동으로 훈련 세트와 테스트 세트로 나누어줌)을 import 하여 사용했다. 그리고 각 특성 간의 단위가 다름을 고려하여 데이터들을 정규화 시켜주었다.
#훈련모델 평가
kn = KNeighborsClassifier()
kn = kn.fit(train_scaled, train_target)
kn.score(test_scaled, test_target)
#전처리(std, mean, stratify) 이전 점수: 0.8951048951048951
#전처리 이후 점수: 0.958041958041958
#직접 셔플 후 전처리할 경우 점수: 0.9710144927536232
#train_test_split에서 stratify를 안할 경우 점수: 0.972027972027972
마지막으로 sklearn의 KNeighborsClassifier을 import 하여 KNN 알고리즘을 사용해 본 모델을 훈련하고 이를 평가해 보았다. 여러 가지 방법을 사용해본 결과 train_test_split에서 stratify를 안 할 경우가 0.97으로 가장 높은 점수를 얻었음을 확인할 수 있었다. 여기서 점수는 이 모델의 정확도로써 테스트 세트의 정답률을 의미한다.
이번에는 가장 기본적인 회귀 알고리즘인 KNN 알고리즘을 사용해 머신러닝 모델을 제작해보았다. 다음에는 다른 회귀 알고리즘들 또한 사용해볼 예정이다.
'개인공부 > 데이터 사이언스' 카테고리의 다른 글
| 앙상블 기법 (0) | 2024.01.11 |
|---|---|
| 로지스틱 회귀 (0) | 2022.03.14 |
| 신뢰도 높은 리뷰 탐색 프로젝트(파이어베이스, 파이썬) (0) | 2021.03.23 |
| Selenium을 이용한 미세먼지 크롤러 만들기(2) (0) | 2021.03.18 |
| Selenium을 이용한 미세먼지 크롤러 만들기(1) (0) | 2021.03.18 |