선형 모델의 매개변수
선형 모델 y = Wx + b에서 매개변수는 W(가중치)와 b(바이어스) 두 가지입니다. 특징이 d개라면 총 d+1개의 매개변수가 존재합니다.
W는 각 특징이 출력값 y에 미치는 영향, 즉 중요도를 나타냅니다. 키와 몸무게의 관계를 모델링한다면, 키에 해당하는 W는 크게 학습되고 혈액형에 해당하는 W는 0에 가깝게 학습되는 식이죠.
b(바이어스)는 y절편 값으로, 전자공학의 직류 오프셋처럼 신호를 위아래로 이동시켜주는 역할을 합니다.
직선으로 표현이 안 되는 데이터도 있습니다. 앞으로 가다가 다시 뒤로 돌아오는 운동 궤적 같은 경우죠. 이럴 때는 2차 이상의 모델이 필요한데, x², 교차항 x₁x₂ 같은 항들이 추가되면서 매개변수 수가 d²에 비례해 급격히 늘어납니다. 모델이 복잡할수록 표현력은 높아지지만 매개변수 수도 함께 증가하는 트레이드오프가 생깁니다.
특징 공간과 표현 학습
특징 공간(Feature Space) 이란 특징 벡터들이 분포하는 공간입니다. 2차원 특징 공간에서 두 부류의 데이터가 있을 때, 직선 하나로 완벽히 구분할 수 있으면 선형 분리 가능하다고 합니다.
기계학습이 하는 일은 결국 이것입니다.
선형 분리 불가능한 특징 공간 (입력)
↓ [특징 변환]
선형 분리 가능한 특징 공간 (출력)
↓
직선으로 분류 수행
학습이란 선형 분리가 잘 안 되는 공간을 더 잘 되는 공간으로 만들어가는 과정이라고 볼 수 있습니다.
표현 학습(Representation Learning) 은 이 더 좋은 특징 공간을 자동으로 찾는 학습입니다. 딥러닝이 레이어를 여러 개 쌓는 이유가 여기에 있어요. 레이어를 거칠수록 데이터는 점점 분리하기 좋은 표현으로 변환됩니다. 실제로 학습된 딥러닝 네트워크를 시각화해보면, 앞단에는 엣지와 명암 같은 저수준 특징이, 뒤쪽에는 눈, 코, 얼굴 형태 같은 추상적인 특징이 자연스럽게 학습되어 있습니다. 사람이 설계한 게 아니라 학습 결과로 나타나는 구조라는 게 흥미롭습니다.
차원의 저주와 매니폴드 가정
특징 차원이 높아질수록 동일한 밀도의 데이터를 얻기 위한 샘플 수가 지수적으로 증가합니다. 1차원에서 샘플 6개로 충분하던 밀도를, 2차원에서 유지하려면 36개, 3차원에서는 216개가 필요합니다. 이를 차원의 저주(Curse of Dimensionality) 라고 합니다. 과업과 관련 없는 특징을 추가하면 성능이 오히려 떨어지는 이유가 여기에 있습니다.
그렇다면 현실에서 왜 적은 데이터로도 학습이 가능할까요? 매니폴드 가정(Manifold Hypothesis) 덕분입니다.
첫째, 전체 특징 공간의 대부분은 실제 샘플이 발생하지 않는 빈 공간입니다. 둘째, 실제 샘플들은 무작위로 분포하지 않고 어떤 규칙을 가진 다양체(manifold) 위에 모여 있습니다. 숫자 '4' 이미지들의 매니폴드를 예로 들면, 한 방향으로 이동하면 크기가 작아지는 '4'가, 다른 방향으로 이동하면 기울어진 '4'가 나옵니다.
모델이 이 매니폴드를 학습하면, 훈련 집합에 없던 새로운 샘플도 올바르게 예측할 수 있습니다. 이것이 일반화 성능의 원천입니다.
목적 함수 (Cost Function)
학습이란 파라미터를 조정해 훈련 집합을 잘 맞추는 함수를 찾는 과정입니다. 이를 위해 현재 모델이 얼마나 잘못 예측하고 있는지를 수치로 측정하는 목적 함수(Cost Function) 가 필요합니다.
한 가지 짚고 넘어갈 점이 있습니다. 목적 함수의 입력은 데이터 x, y가 아니라 모델 파라미터 θ입니다. x, y는 이미 주어진 상수이고, 내가 조절할 수 있는 건 W와 b뿐이니까요.
선형 회귀에서 가장 많이 쓰는 목적 함수는 평균 제곱 오차(MSE)입니다.
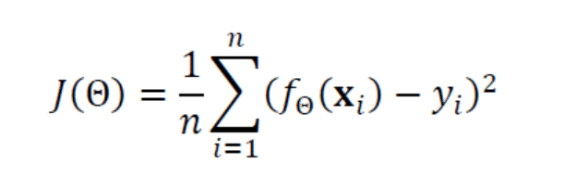
오차를 제곱하기 때문에 방향에 무관하게 크기만 반영되고, 큰 오차에 더 강한 패널티를 줍니다.
학습 목표를 수식으로 표현하면 θ̂ = argmin_θ L(θ), 즉 목적 함수를 최소화하는 파라미터를 찾는 것입니다. 실제로는 해석적으로 한 번에 해를 구하는 게 불가능하기 때문에, 목적 함수가 작아지는 방향으로 파라미터를 조금씩 반복 업데이트하는 수치적 방법을 사용합니다.
과소적합과 과잉적합
모델 복잡도를 선택할 때 두 가지 문제가 생깁니다.
과소적합(Underfitting) 은 모델의 용량이 데이터의 복잡도보다 너무 작을 때 발생합니다. 훈련 집합에서도 오차가 크게 유지됩니다. 1차 모델로 비선형 데이터를 맞추려 할 때가 전형적인 예입니다.
과잉적합(Overfitting) 은 반대입니다. 훈련 집합 오차는 0에 가깝지만, 처음 보는 데이터에서 오차가 매우 큽니다. 학습 과정만 봐서는 이상을 감지하기 어렵다는 점에서 더 조심해야 하는 문제이기도 합니다.
Bias-Variance Trade-off
모델의 적합 정도를 진단하는 두 가지 지표가 있습니다.
Bias(편향) 는 훈련 집합에서의 오차입니다. Bias가 크면 Underfitting입니다. Variance(분산) 는 서로 다른 훈련 집합으로 학습한 모델들이 동일한 입력에 대해 얼마나 다른 예측을 하는지를 나타냅니다. Variance가 크면 Overfitting입니다.
두 지표는 트레이드오프 관계에 있고, 최적 모델은 Bias + Variance의 합이 최소가 되는 지점입니다.

모델 선택 전략
테스트 집합은 학습 도중 사용할 수 없습니다. 그래서 훈련 집합의 일부를 검증 집합으로 분리해 과적합 여부를 판단합니다. 간단하긴 하지만, 전체 데이터의 일부를 학습에 쓰지 못하는 손실이 생깁니다.
이 문제를 해결하는 방법이 K-Fold 교차 검증입니다. 전체 데이터를 K개의 폴드로 나누고, 매 반복마다 하나씩 검증에 사용하는 방식입니다. K=4라면 이렇게 됩니다.
Iteration 1: [폴드1, 폴드2, 폴드3 → 학습] + [폴드4 → 검증]
Iteration 2: [폴드1, 폴드2, 폴드4 → 학습] + [폴드3 → 검증]
Iteration 3: [폴드1, 폴드3, 폴드4 → 학습] + [폴드2 → 검증]
Iteration 4: [폴드2, 폴드3, 폴드4 → 학습] + [폴드1 → 검증]
최종 성능 = 4개 검증 성능의 평균
모든 샘플이 정확히 한 번씩 검증에, K-1번씩 학습에 사용됩니다. 데이터는 낭비 없이 활용할 수 있지만 K번 학습을 반복해야 한다는 점은 감수해야 합니다.
부트스트랩(Bootstrap) 은 무작위 복원 추출로 학습/검증을 T번 반복해 성능을 추정하는 방법입니다. T를 늘릴수록 더 안정적인 추정이 가능합니다.
규제 (Regularization)
규제란 과잉적합을 막을 수 있는 모든 수단과 방법입니다. 과잉적합의 근본 해결책은 데이터를 늘리는 것이지만, 의료 영상처럼 데이터 획득이 어려운 분야에서는 다른 기법들이 필요합니다.
데이터 증강 (Data Augmentation)
기존 샘플에 Translation(이동), Rotation(회전), Scaling(크기 조절) 같은 변환을 적용해 새로운 데이터를 합성하는 방법입니다. 매니폴드 위에서 자연스럽게 발생할 수 있는 데이터를 시뮬레이션으로 만들어내는 것이죠.
하나의 샘플로 수백~수천 개의 데이터를 만들 수 있어서, 현재는 어떤 머신러닝/딥러닝 방법을 쓰더라도 표준으로 적용됩니다. 단, 변환 강도가 과도하면 역효과가 납니다. 숫자 '9'를 180도 회전하면 '6'이 되어버리는 것처럼요.
가중치 감쇄 (Weight Decay)
과잉적합을 유발하는 뾰족한 함수는 가중치 값이 매우 클 때 나타납니다. 이 관찰로부터, 목적 함수에 가중치를 작게 만드는 항을 추가하는 방법이 가중치 감쇄입니다.
L(θ) = L₁(θ) + λ·‖θ‖²
λ가 크면 가중치를 강하게 억제하고, 작으면 억제 효과가 약해집니다. 실제로는 b는 규제하지 않고 W만 규제하는 게 일반적인데, b는 과잉적합을 유발하는 변수가 아니기 때문입니다.
학습의 유형
지도 / 비지도 / 강화학습
지도 학습(Supervised Learning) 은 입력 x와 레이블 y가 모두 주어진 학습입니다. y가 연속값이면 회귀, 범주값이면 분류 문제가 됩니다.
비지도 학습(Unsupervised Learning) 은 레이블 없이 x만으로 학습합니다. 군집화(Clustering), 밀도 추정 등이 대표적입니다. 유튜브 추천 알고리즘이 좋은 예인데, 사용자가 선호도를 직접 입력하지 않아도 시청 기록의 유사도로 군집화해 콘텐츠를 추천합니다.
강화 학습(Reinforcement Learning) 은 레이블 대신 보상(Reward)으로 학습합니다. Agent가 Environment에 action을 하면 Environment는 다음 state와 reward를 반환합니다. 매 행동마다 정답이 주어지는 게 아니라 일련의 행동 끝에 최종 보상을 받는 구조입니다.
준지도 학습(Semi-Supervised Learning) 은 일부 데이터만 레이블이 있는 경우입니다. 레이블 없는 데이터의 분포 정보를 활용해 Decision Boundary를 더 좋은 위치에 설정합니다.
오프라인 / 온라인 학습
오프라인 학습은 데이터가 고정된 상태에서 일반적인 배치 방식으로 학습합니다. 온라인 학습은 데이터가 실시간으로 갱신되는 환경에서의 학습입니다.
Deep Neural Network는 온라인 학습에 취약합니다. 새로운 데이터로 재학습하면 기존 데이터에 대한 성능이 급격히 떨어지는 파괴적 망각(Catastrophic Forgetting) 현상이 발생하기 때문입니다. 이를 해결하려는 연구 분야를 연속 학습(Continual Learning) 또는 평생 학습(Lifelong Learning)이라고 합니다.
결정론적 / 확률적 학습과 앙상블
결정론적 학습은 동일한 데이터로 학습하면 항상 같은 파라미터가 나옵니다. 확률적 학습은 난수를 추가해 매번 조금씩 다른 모델이 나오도록 합니다.
Deep Neural Network는 모두 확률적 방식으로 학습되는데, 여기서 앙상블(Ensemble) 의 이점이 생깁니다. 조금씩 다른 특성을 가진 여러 모델의 예측을 평균 내면 개별 모델의 편향이 희석되어 성능이 비약적으로 향상됩니다. 또한 여러 모델의 예측을 종합하면 신뢰도도 추정할 수 있습니다. 4개 모델 중 3개가 '남자'라고 예측했다면 남자일 확률을 75%로 표현하는 식이죠. 한 명의 의사보다 8명의 의사 소견을 종합한 진단이 더 신뢰할 수 있는 것과 같은 원리입니다.
분별 모델과 생성 모델
분별 모델(Discriminative Model) 은 P(y|x)를 추정합니다. 입력 x를 받아 클래스 y를 판별하는 모델로, 이미지를 보고 남자/여자를 분류하는 게 예입니다.
생성 모델(Generative Model) 은 P(x) 또는 P(x|y)를 추정합니다. 데이터 자체의 분포를 모델링하고, 이 분포에서 새로운 샘플을 생성합니다.
분별 모델은 x를 받아 스칼라 y 하나를 출력하지만, 생성 모델은 y를 조건으로 100×100 픽셀 이미지 전체, 즉 1만 개의 값을 만들어내야 합니다. 아름다운 그림을 판단하는 것과 직접 그리는 것의 차이라고 생각하면 됩니다. 그럼에도 현재 딥러닝 기반 생성 모델은 사람이 만든 것과 구분하기 어려운 수준의 이미지와 텍스트를 만들어낼 수 있습니다.
결국 머신러닝의 목표는 결국 하나입니다. 훈련 데이터에서 배운 것을 처음 보는 데이터에도 잘 적용하는 것. 이를 일반화(Generalization)라고 하며, 지금까지 다룬 모든 개념들은 이 목표를 달성하기 위한 도구들입니다.
'학교공부 > 딥러닝' 카테고리의 다른 글
| [딥러닝] 딥러닝 최적화(1) (0) | 2026.03.24 |
|---|---|
| [딥러닝] 다층 퍼셉트론 (0) | 2026.03.05 |
| [딥러닝] 퍼셉트론 (0) | 2026.03.05 |
| [딥러닝] 기계학습과 수학(2) (0) | 2026.03.04 |
| 딥러닝 [수정중] (0) | 2025.12.12 |