
Cache
컴퓨터 시스템에서 빠른 데이터 엑세스를 위해 사용되는 고속 메모리로 CPU와 메인메모리 사이에 위치한다.
컴퓨터가 실행하는 프로그램은 메인 메모리에 저장되어 있지만 CPU가 메인 메모리에서 데이터를 가져오기까지는 상당한 시간이 걸리기 때문에, 프로그램의 실행속도를 향상시키기 위해 캐시가 도입된 것이다. 만약 우리가 책장에서 책을 가져와 책상 위에서 사용한다고 가정해보자. 하지만 책장에서 매번 책을 가져오기에는 번거롭고 시간도 비교적 오래 걸린다. 그래서 앞으로는 책상 위에 작은 책상용 책꽂이를 마련해 자주 사용하는 책 몇 권을 꽂아두기로 했다. 이렇게 책상용 책꽂이를 사용하게 되면서 우리는 책을 조금 더 빠르고 쉽게 가져올 수 있게 되었다. 여기서 책장은 메인 메모리, 책은 데이터, 책장은 CPU, 책상용 책꽂이는 캐쉬라고 생각할 수 있다. 캐시는 이처럼 속도와 용량 측면에서 메인 메모리보다 빠르고 작은 용량을 가지고 있다. 때문에 CPU는 데이터를 필요로 할 때 우선적으로 캐시에 접근하여 데이터의 유무를 확인하고 데이터가 존재하면 바로 접근하여 데이터를 가져오고 없다면 그제야 메인 메모리로 접근하게 된다.
아래는 캐시와 관련된 몇가지 용어들이다.
Hit – cpu가 찾는 데이터가 캐시 위에 있을 때
Hit rate – hit이 나는 비율
Miss – cpu가 찾는 데이터가 캐시 위에 없을 때
Miss rate – miss 나는 비율
Miss penalty – miss가 나서 허비된 시간
Effective memory access time(EMAT) – cpu가 찾는 데이터를 실제로 가져오는 시간
하나의 캐시에서 -> EMAT = T_c + m * T_m (T_c는 cache access time, m은 miss rate, T_m은 miss penalty)
여러 개의 캐시에서 -> EMAT_i = T_i + m * EMAT_(i+1) (T_i는 i level cache의 access time)
Block – 캐시에서 데이터를 저장하는 단위
Direct-mapped cache
Direct-mapped cache는 캐시 메모리의 한 종류로, 가장 간단한 형태의 캐시이다. 여기서는 편의상 DM cache라고 부르도록 하겠다. DM cache는 메인 메모리의 블록들을 캐시의 고유한 위치에 일대일 매핑하는 방식으로 동작한다.


DM cache의 원래를 이해하기 위해 위 그림과 같이 8개의 주소를 가진 메인메모리와 4개의 캐시라인을 가진 DM cache를 가정해보자. 먼저 DM cache는 캐시 라인의 인덱스와 주소의 일부를 매핑하여 캐시 라인에 할당한다. 예를 들어, 주소의 하위 비트를 사용하여 캐시 라인의 인덱스를 결정할 수 있는데, 위 예에서는 3개의 비트로 인덱스를 표현할 수 있다. 만약 주소 2에 있는 데이터를 가져와야 한다고 가정해보면 주소 2는 이진수로 010으로 표현되고 이 때문에 메인메모리 주소 2에 위치한 데이터는 캐시 메모리 주소의 하위 3비트가 010인 캐시 라인, 즉 3번째 라인에 매핑된다.
즉 메인 메모리 주소의 하위 몇 비트(위 예에선 3비트)에 해당하는 인덱스의 캐시 라인(위 예에선 3번째 라인)에 매핑되는 것이다.
이제 데이터를 가져오기 위해 캐시에 접근할 때는 해당 인덱스에 있는 캐시 라인을 확인하게 된다. 해당 캐시 라인에 데이터가 존재하면 캐시 히트가 발생하고 데이터를 즉시 사용할 수 있다. 그렇지 않은 경우는 캐시 미스가 발생하며, 메인메모리로부터 해당 블록을 가져와 캐시에 저장한 후 데이터를 사용하게 된다.

더 자세히 살펴보면 위와 같은 방식으로 동작한다. 우선 index를 확인한 후 해당 캐시 index에 해당하는 부분(해당 캐시 라인)으로 가서 tag(캐시 라인에서의 데이터의 위치)를 확인하여 있는지 없는지 판단하는 방식으로 사용된다.

추가로 Valid 비트를 두어서 content가 유효한지 그렇지 않은지 판단한다.
Write back / Write through
Write back
데이터를 먼저 캐시에만 업데이트하고, 나중에 메인 메모리로 업데이트하는 방식

데이터가 캐시에 쓰여지면 해당 블록에 dirty 비트가 설정되어 해당 데이터가 메모리와 동기화되지 않은 상태임을 나타낸다.
write back은 업데이트를 지연시키기 때문에, 메모리와의 통신 횟수를 줄여 성능을 향상시킬 수 있다. 하지만 캐시와 메모리 사이의 데이터 일관성 관리(dirty bit)가 필요하다.
Write through
데이터를 캐시와 메인메모리에 동시에 업데이트하는 방식

write through는 메모리와 캐시의 데이터를 항상 일치시킴으로써 데이터 일관성을 보장한다. 하지만 매 write마다 메모리 업데이트가 발생하므로 성능에 영향을 줄 수 있다.
보통 L1은 write back, L2/L3는 write through으로 처리하는 경우가 많다.
Block size
블록 사이즈를 키우면 spartial locality가 높아지고 이는 miss rate을 낮춘다. 하지만 블록 사이즈를 키우면 일정 크기까지는 miss rate이 낮아지다가 어느 순간부터는 miss rate이 다시 높아진다. 왜냐하면 그만큼 블록의 개수가 적어져서 같은 블록에 중복되는 메모리 주소가 증가하고 이는 conflict를 증가시키 때문이다.
Fully associative cache
가장 유연한 캐시 구조 중 하나로, 메인 메모리의 모든 주소를 캐시 라인에 임의로 매핑할 수 잇는 구조

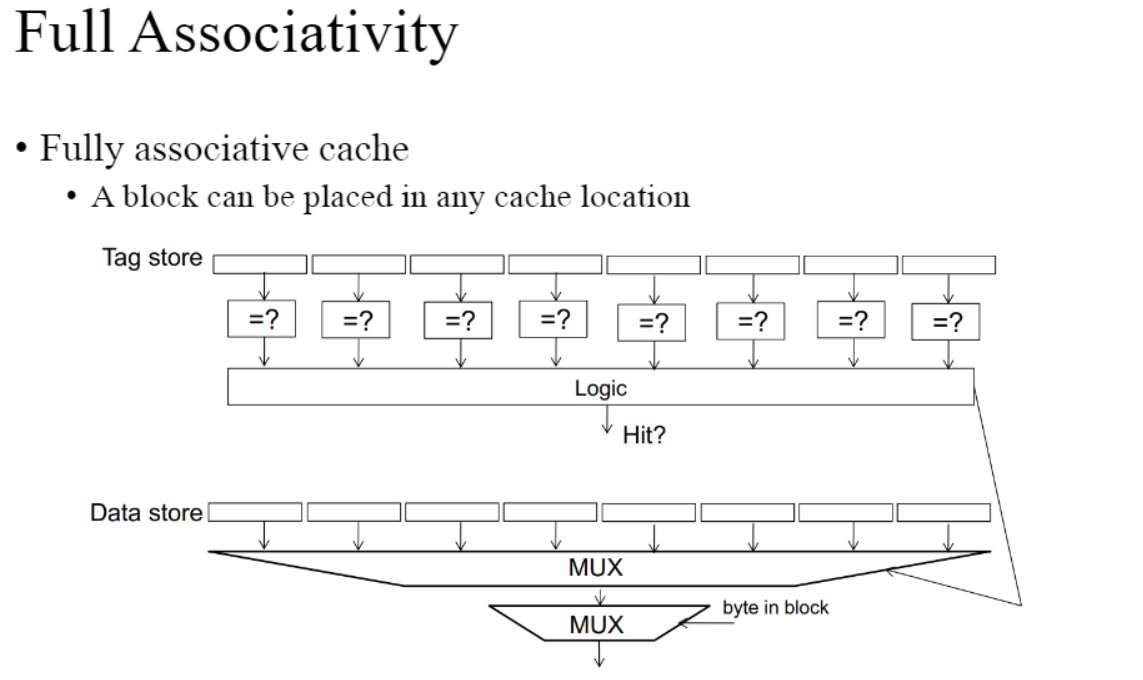
hit rate은 높고 유연하지만 태그 오버헤드가 높고 비용과 복잡성이 높다.
Set associative cache
direct mapped cache와 fully associative cache의 장점을 조합한 구조로, direct mapped cache에서 특정 주소가 여러 개의 캐시 블록에 매핑 가능하게 하여 hit rate은 높이되 태그 오버헤드는 낮춘 cache


'학교공부 > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터 구조] A Single Cycle MIPS Processor (0) | 2024.10.13 |
|---|---|
| [컴퓨터 구조] Branch prediction (0) | 2024.10.13 |
| [컴퓨터 구조] Memory Hierarchy (0) | 2023.06.03 |
| [컴퓨터 구조] Multithreading (0) | 2023.06.03 |
| [컴퓨터 구조] Handling Dependences (0) | 2023.05.08 |