
BERT는 transformer의 인코더 구조만을 사용하여 만든 bidirectional 모델이다. BERT 논문에서는 'Deep'이라는 글자를 강조했는데, 이는 기존의 language representation 모델들과 다르게 자신들의 모델 구조가 진정한 의미의 양방향 representation을 가능하게 했다는 것을 말하고자 한 것으로 보인다. BERT의 가장 큰 특징은 한번 Pre-training해 놓으면 모델 구조를 바꾸지 않고도 Fine-tuning 만으로 여러 NLP task에 적용할 수 있다는 것이다. 이처럼 개량 방식은 매우 간단하지만 여러 분야에서 SOTA를 달성할 만큼 우수한 모델임이 증명되었다.
Introduction
LM pretraining은 BERT 이전에도 다양한 NLP task에서 그 효과를 입증하고 있었다. 그리고 이러한 Pretrained LM을 downstream task에 적용하기 위한 전략은 Feature-Based와 Fine-Tuning이 존재한다.
Feature-Based model의 대표적인 예로는 ELMo를 들 수가 있는데, ELMo는 pretrained model을 추가적인 feature로 사용하여, 각 task마다 아키텍처의 구조를 변경하는 task-specific architecture을 사용한다.

ELMo 또한 양방향 모델이긴 하지만 아래 그림과 같이 left to right 모델과 right to left 모델을 단순히 합쳐 만든 것이기 때문에 진정한 양방향 모델이라 하기에는 어려움이 있다고 말하고 있다.

반면 BERT는 masked language 모델과 Fine-Tuning을 사용하여 GPT나 ELMO와 같은 단방향 모델의 한계점을 극복할 수 있었다고 한다.
Related Work
관련 연구에서는 pretraining language model의 역사에 대해 짧게 리뷰하고 있다.
첫 번째로 'Unsupervised Feature Based Approches'라는 관점에서 볼 때, 초기에는 pretrained language model들이 주로 비지도 학습을 기반으로 한 feature 추출 방식으로서 사용되었다. 초기의 Word2Vec이나 GloVe와 같은 모델들은 텍스트 데이터를 활용하여 단어들을 벡터로 임베딩(word embedding)함으로써 단어의 의미와 유사성을 수치화했다. 하지만 word embedding만으로는 문맥을 충분히 반영하지 못한다는 문제가 있었고, 이를 위해 'Contextualized word embedding'이 개발되었다. 이 방식의 대표적인 예는 ELMo로, 문맥에 따라 단어의 의미를 다르게 표현하는 것을 목표로 하였다. 또한 이러한 사전 훈련된 특징을 다양한 downstream task에 활용하는 방식이 개발되었다.
두 번째는 'Unspervised Fine-tuning Approches'이다. 초기에는 unlabeled text에서 word embedding 파라미터를 pre-train하는 방식으로 진행되었다. 최근에는 unlabled text에서 sentence encoder나 document encoder를 pre-train하게 되었으며, 이를 supervised downstream task에 fine-tuning하는 연구가 진행되었다. 이러한 방식의 장점은 적은 수의 파라미터로도 학습이 가능하다는 것으로, GPT는 이를 통해 SOTA를 달성하였다.
마지막으로는 Supervised data로부터 전이 학습(transfer learning)을 하는 연구이다. 이는 NLI나 Translation 등 많은 데이터셋이 필요한 Supervised task에서 효과적인 전이학습을 보여줬다.
BERT Framework
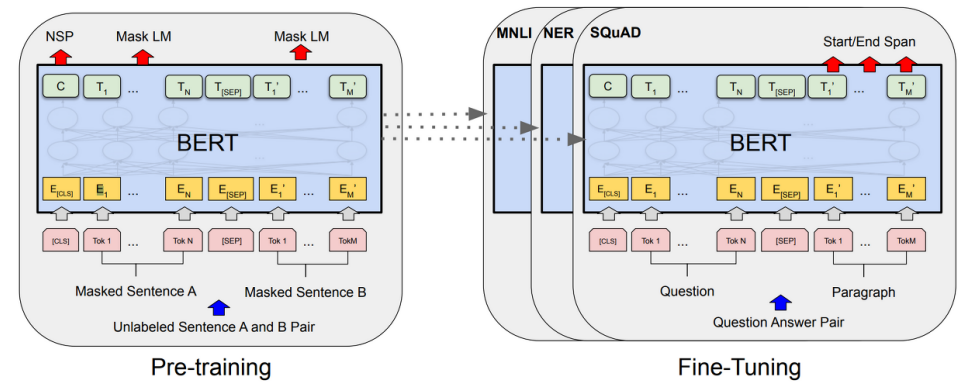
BERT의 프레임워크는 크게 Pre-training과 Fine-Tuning 두 부분으로 구성된다. Pre-training 과정에선 unlabeled data를 가지고 각기 다른 task를 동시에 사전학습하여 초기 가중치를 설정한다. 이 단계에서 모델은 문장 내에서 단어들의 상황과 문맥을 이해하고, 언어적인 특성을 학습한다. Fine-Tuning에서는 Pre-training에서 만들어진 모델의 일부 레이어나 가중치를 변경하여 downstream task를 수행하기 더욱 적합하게 만든다. 즉, Pre-training에서는 전체 모델의 큰 틀을 만들고, Fine-Tuning에서는 모델이 다양한 작업을 수행할 수 있도록 수정한다.
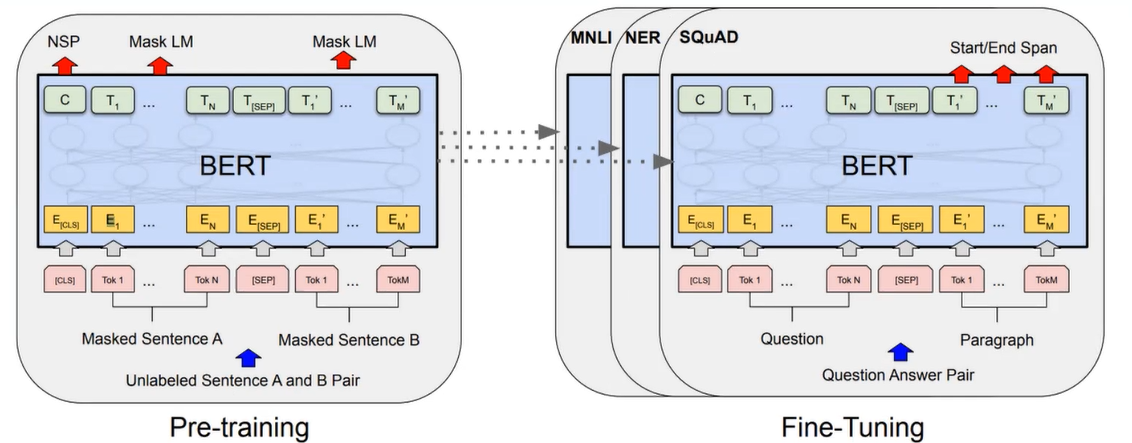
BERT 모델은 여러 개의 양방향 Transformer Encoder 레이어를 쌓아올린 구조를 가지고 있으며, 각 Encoder 레이어는 Self-Attention 메커니즘을 이용하여 토큰 간의 의미 관계를 모델링하고, 다양한 특징을 추출한다.


위 그림은 BERT base 모델과 BERT large 모델을 비교하고 있다. 여기서 L은 인코더의 수를, H는 인코더에서 사용되는 뉴런의 개수인 hidden size를, A는 multi head attention의 head 수를 뜻한다.
I/O Representation
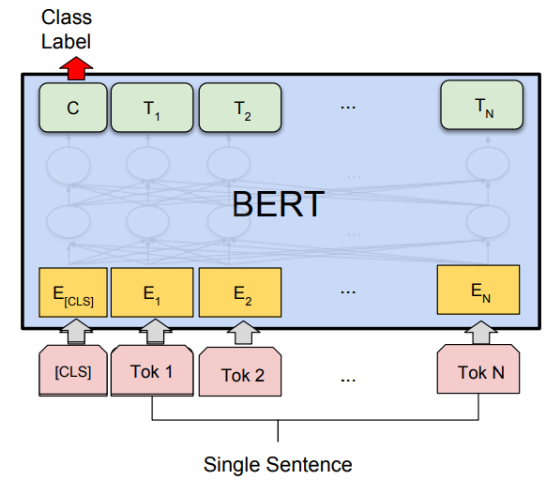
우선 입력되는 문장은 [CLS] 토큰과 [SEP] 토큰을 갖는다. [CLS] 토큰은 문장의 시작을 나타내며, 문장 전체의 의미를 대표하는 역할을 담당한다. 분류 작업의 경우 [CLS] 토큰에 대한 은닉 상태를 사용하여 문장의 클래스를 예측할 수 있다. 그리고 [SEP] 토큰은 문장 간의 경계를 구분하는 역할을 한다.
BERT는 입력 문장에 대해 세 가지 임베딩 층을 사용하는데, Token Embeddings, Segment Embedding, Position Embedding이 바로 그것이다.

우선 Token Embedding에는 Wordpiece 방식이 사용된다. Wordpiece는 서브워드 분리(subword tokenization) 기법 중 하나로, 단어를 더 작은 부분으로 쪼개는 방식을 의미한다. 예를 들어, running이라는 단어는 run과 ##ing 라는 두 개의 서브워드로 분리될 수 있다. 이를 통해 입력 문장의 문맥을 이해하고 다양한 언어적 특성을 습득할 수 있다.
Segment Embedding은 두 개 이상의 문장을 구분하기 위해 사용되는 임베딩이다. 보통 각 토큰에 값을 부여하여 문장의 소속을 표시한다. 첫 번째 문장에는 0을, 두 번째 문장에는 1을 부여하는 식이다.
Position Embedding은 각 토큰의 위치 정보를 학습하기 위한 임베딩이다.
이러한 세가지 임베딩의 결과는 Transformer Encoder 레이어의 입력이 된다.
Pre-training BERT
Pre-training 단계에서 BERT는 두 가지 학습 방식을 동시에 사용하는데, Masked Language Model(MLM)과 Next Sentence Prediction(NSP)가 바로 그것이다.
1. Masked Language Model
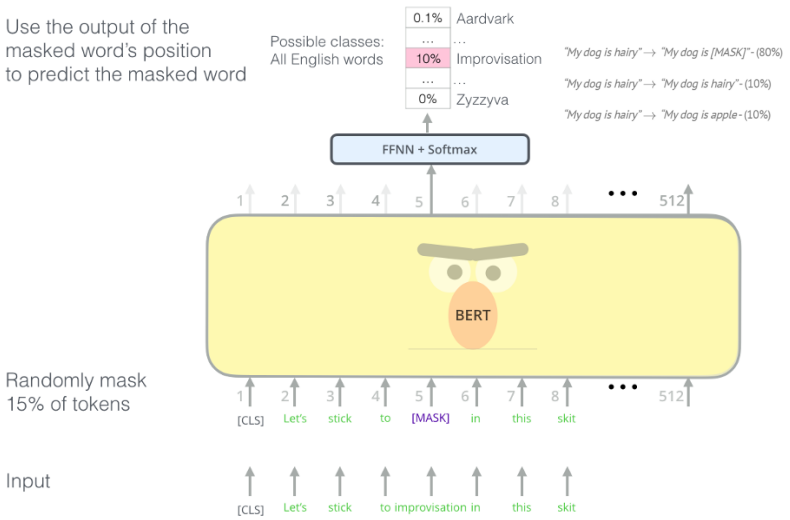
MLM은 문장 내에서 일부 단어를 랜덤하게 마스킹하고, 모델이 이러한 마스킹된 단어를 예측하도록 하는 작업이다. 예를 들어, "The cat is on the [MASK]"라는 문장에서 [MASK]에 어떤 단어가 와야 하는지 예측한다. 하지만 이러한 [MASK] 토큰은 Pre-training 데이터에서만 존재하기 때문에 실제 downstream task를 위한 Fine-Tuning 과정에서는 [MASK] 토큰이 존재하지 않는다. 따라서 마스킹 방식만으로는 Pre-trained 모델을 얻을 수는 있지만 Pre-training과 Fine-tuning 사이의 불일치가 발생한다.
이를 해결하기 위해 전체 토큰의 15%를 무작위로 선택한다. 그리고 그 토큰들 중
80%는 [MASK] token으로 ("The cat is on the table" -> "The cat is on the [MASK]"),
10%는 random word로 ("The cat is on the table" -> "The cat is on the roof")
10%는 그대로 ("The cat is on the table" -> "The cat is on the table")
변경한다. 이후 각 토큰에 대해 예측을 진행하고, Cross-Entropy Loss라는 손실 함수를 사용하여 모델을 학습시킨다.
2. Next Sentence Prediction
기존의 모델들에서는 Pre-training 단계에서 문장 사이 관계를 파악하는 능력을 따로 학습하지 않았기 때문에 그 부분에 대한 성능이 상당히 떨어졌다. 때문에 BERT에서는 NSP를 통해 두 개의 문장이 이어지는 문장인지 아닌지를 판단할 수 있도록 모델을 훈련하였다.

우선 50:50 비율로 실제 이어지는 두 개의 문장과, 랜덤으로 이어 붙인 두 개의 문장이 주어진다. 그 후 예측을 진행하여 실제로 연속된 문장이라고 추정된다면 'IsNext' 레이블을, 랜덤한 문장 쌍으로 추정된다면 'NotNext' 레이블을 부여한다. 예측 과정에서는 처음 입력되었던 [CLS] 토큰의 은닉상태를 활용한다. 이러한 NSP 과정을 통해 BERT는 문장 간의 관계를 학습하고 문맥을 이해하는 능력을 향상시킨다.
Fine-Tuning
BERT는 각기 다른 NLP task를 위해 따로 Fine-tuning 과정이 필요하다.
1. Sentence Pair Classification Tasks
두 문장이 주어졌을 때 한 문장이 다른 문장과 논리적으로 어떠한 관계에 있는지를 분류하는 task이다. 이는 문장 쌍을 입력받는 대표적인 task 중 하나로, 자연어 추론(NLI)이 이에 포함된다. 우선 입력되는 문장을 [SEP] 토큰으로 구분하고 [CLS] 토큰이 두 문장의 관계를 나타내도록 학습시킨다.
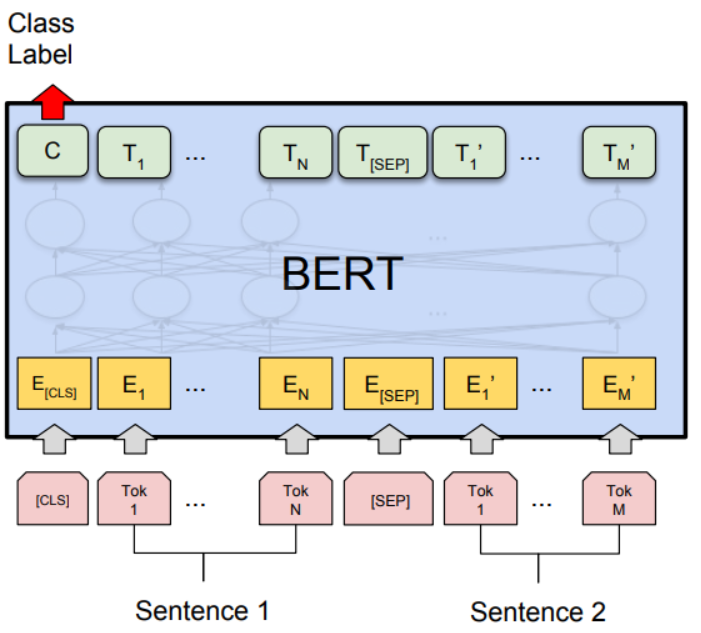
2. Single Sentence Classification Tasks
하나의 문장을 입력받아 해당 문장의 클래스 또는 레이블을 분류하는 작업을 의미한다. 이러한 작업은 텍스트 분류나 감정 분석과 같은 작업에서 사용된다.
3. Question Answering Tasks
주어진 질문에 대한 답변을 찾는 NLP task를 말한다. 이러한 작업은 기계독해나 정보검색과 같은 분야에서 사용된다.
[SEP] 토큰으로 질문과 본문을 구분하며, 본문 속 정답의 시작 인덱스와 마지막 인덱스를 출력하도록 학습된다.

4. Single Sentence Tagging Tasks
하나의 문장에 대해 각 단어 또는 토큰에 대한 태그나 레이블을 예측하는 task이다. 예를 들어 "고양이가 테이블에 앉았다"라는 문장의 품사를 예측하는 작업을 수행한다면, '고양이'에는 명사 태그, '앉았다'에는 동사 태그가 부여된다.

'개인공부 > 데이터 사이언스' 카테고리의 다른 글
| GAN 논문 리뷰 (2) | 2024.02.13 |
|---|---|
| AlexNet 논문 리뷰 (0) | 2024.02.13 |
| Attention Is All You Need 논문 리뷰 (1) | 2024.02.13 |
| 편향과 분산 (0) | 2024.01.11 |
| 앙상블 기법 (0) | 2024.01.11 |