
머신러닝에서 편향과 분산은 모델의 성능을 평가하고 최적화하는 데 중요한 역할을 한다. 편향은 모델의 예측값이 실제값과 얼마나 차이가 나는지를 나타내며, 분산은 예측값들이 얼마나 넓게 퍼져있는지를 보여준다.
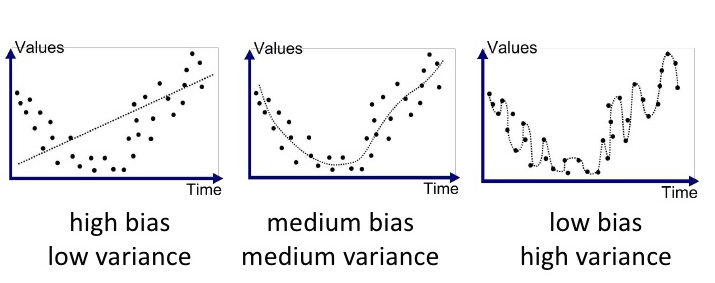
이미지에서 볼 수 있듯이, 높은 편향과 낮은 분산을 가진 모델은 단순한 패턴을 보이며 데이터의 복잡성을 제대로 잡아내지 못해 과소적합 상태에 빠진다. 반면, 낮은 편향과 높은 분산을 가진 모델은 데이터의 노이즈까지 학습하여 과대적합 상태가 된다.
좋은 모델을 만들기 위해서는 편향과 분산 사이의 균형을 찾는 것이 중요하다. 하지만 이 둘은 서로 상충관계에 있어, 하나를 개선하려고 하면 다른 하나가 악화되는 경향이 있다. 따라서 모델 개발자는 적절한 복잡도를 가진 모델을 설계하여 두 요소 사이의 최적점을 찾아야 한다.
회귀 문제에서는 주로 평균제곱오차(MSE)를 사용하여 모델의 성능을 평가한다. 이 지표는 편향과 분산 모두를 고려하므로, 전반적인 모델의 성능을 잘 반영한다. 결국, 효과적인 머신러닝 모델을 개발하기 위해서는 데이터의 특성을 잘 이해하고, 적절한 모델 복잡도를 선택하며, 필요에 따라 정규화 기법을 적용하는 등의 방법으로 편향과 분산의 균형을 맞추는 것이 핵심이다.
'개인공부 > 데이터 사이언스' 카테고리의 다른 글
| BERT 논문 리뷰 (2) | 2024.02.13 |
|---|---|
| Attention Is All You Need 논문 리뷰 (1) | 2024.02.13 |
| 앙상블 기법 (0) | 2024.01.11 |
| 로지스틱 회귀 (0) | 2022.03.14 |
| 최근접 이웃(K-Nearest Neighbor) 알고리즘을 이용한 종양 판별 모델 만들기 (0) | 2021.10.03 |