
오늘은 파이썬을 사용하여 네이버 e북에서 Top 1~100를 차지하고 있는 책들의 정보를 크롤링한 뒤 카테고리를 카운팅해서 어떤 종류의 책이 인기가 많은지에 대해 살펴보았다.
전체 코드는 다음과 같다.
import requests
from bs4 import BeautifulSoup
dic = {}
for page in range(1, 6):
print("page ", page)
print("")
raw = requests.get("https://series.naver.com/ebook/top100List.nhn?page=" + str(page))
html = BeautifulSoup(raw.text, "html.parser")
book = html.select("div#content li")
for b in book:
rank = b.select_one("span.num").text
title = b.select_one("a strong").text
writer = b.select_one("span.writer").text
print(rank, "제목:", title, ", 저자:", writer)
print("")
try:
href = b.select_one("a").get("href")
href_raw = requests.get("https://series.naver.com" + href)
href_html = BeautifulSoup(href_raw.text, "html.parser")
content = href_html.select_one("div#content")
category = content.select("li.info_lst li")
if(len(category) == 5):
category_name = category[2].select_one("a").text
else:
category_name = category[3].select_one("a").text
if(category_name not in dic):
dic[category_name] = 1
else:
dic[category_name]+=1
except:
if("19" not in dic):
dic["19"] = 1
else:
dic["19"]+=1
for key, value in dic.items():
print(key, value)
아래 링크에서는 파이썬을 사용해 데이터를 크롤링하는 방법에 대해 상세히 설명하고 있다. 이 링크를 참고함으로써 BeuatifulSoup에서 html태그를 사용하는 방법에 대해 좀더 확실하게 이해할 수 있었다.
https://book.coalastudy.com/data_crawling/
코딩을 몰라도 쉽게 만드는 데이터수집기
이 자료는 코딩좀알려주라(코알라)에서 배포하는 무료 인터넷 자습자료입니다.
book.coalastudy.com
import requests
from bs4 import BeautifulSoup
dic = {}
우선 Requests와 BeautifulSoup 모듈을 가져오고 카테고리를 넣어줄 딕셔너리를 만들어준다.
for page in range(1, 6):
print("page ", page)
print("")
raw = requests.get("https://series.naver.com/ebook/top100List.nhn?page=" + str(page))
html = BeautifulSoup(raw.text, "html.parser")
네이버 e북에서 인기순위 Top100은 아래와 같이 한페이지에 20권씩 5페이지로 이루어져있다. 때문에 for문을 통해 페이지 수를 구분하고 페이지마다 데이터를 불러와 BeutifulSoup를 이용해 파싱했다.

book = html.select("div#content li")
for b in book:
rank = b.select_one("span.num").text
title = b.select_one("a strong").text
writer = b.select_one("span.writer").text
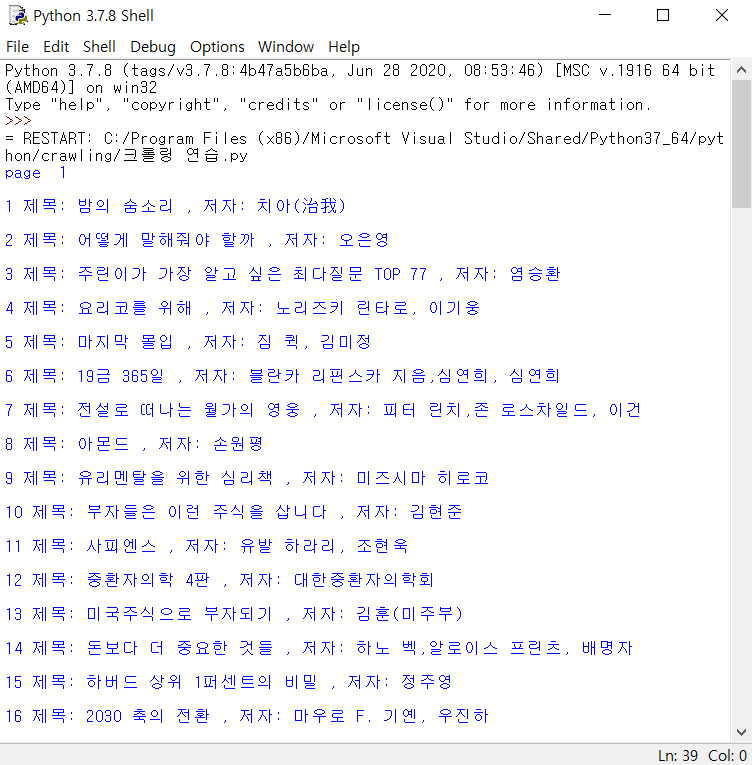
print(rank, "제목:", title, ", 저자:", writer)
print("")
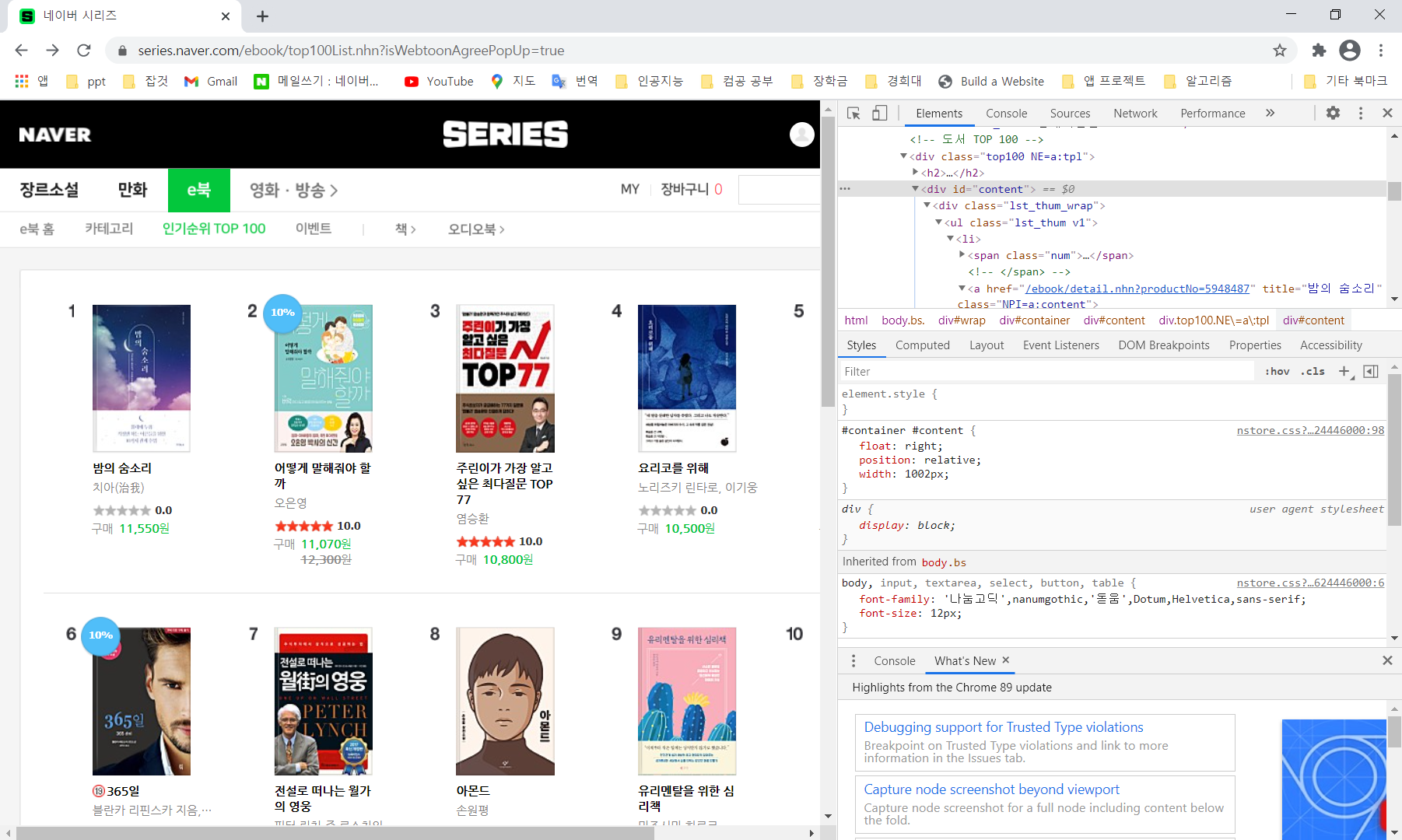
id가 "content"인 div태그를 가진 컨테이너(class가 "lst_thum_wrap"인 div태그를 사용해도 동일한 결과가 나온다)들을 select로 모두 가져오고 각 책의 순위, 제목, 저자 정보를 가져와 아래와 같이 출력시켰다.
try:
href = b.select_one("a").get("href")
href_raw = requests.get("https://series.naver.com" + href)
href_html = BeautifulSoup(href_raw.text, "html.parser")
content = href_html.select_one("div#content")
category = content.select("li.info_lst li")
다음은 카테고리 정보를 가져오는 과정이다. 카테고리 정보는 각 책들의 링크로 직접 들어가 가져와야하기 때문에 a태그에 적혀있는 링크를 가져온 뒤, 첫페이지에서 했던 것과 마찬가지로 그 링크의 정보를 requests로 가져와 파싱했다.
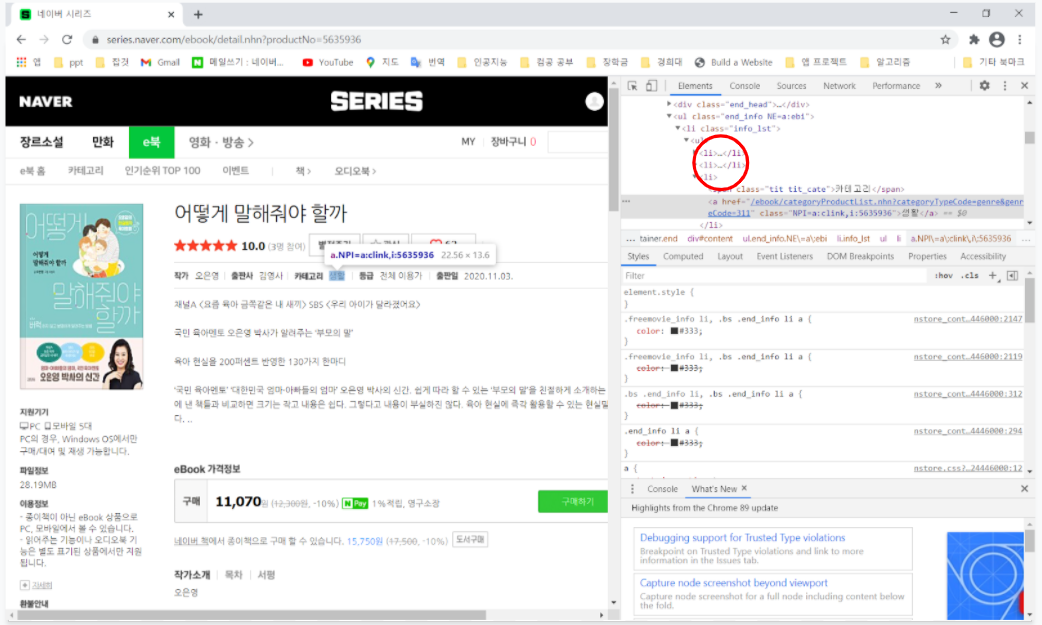
그후 카테고리 정보가 위치한 태그를 찾아본 결과 카테고리 정보는 class가 "info_lst"인 li 태그 안의 3번째 li 태그에 위치해있었다.
if(len(category) == 5):
category_name = category[2].select_one("a").text
else:
category_name = category[3].select_one("a").text
하지만 실질적으로 코드를 작성해 실행시켜보니 출판사와 카테고리가 섞여나오는 문제가 발생했다. 왜 그런가 하고보니 외국서적의 경우 번역가에 대한 li 태그가 추가되어 순서가 변경되었기 때문이었다. 문제해결을 위해 if문을 통해 li 태그가 5개이면 2번째 li 태그를 사용하고 6개이면 3번째 li 태그를 사용하게 했다.
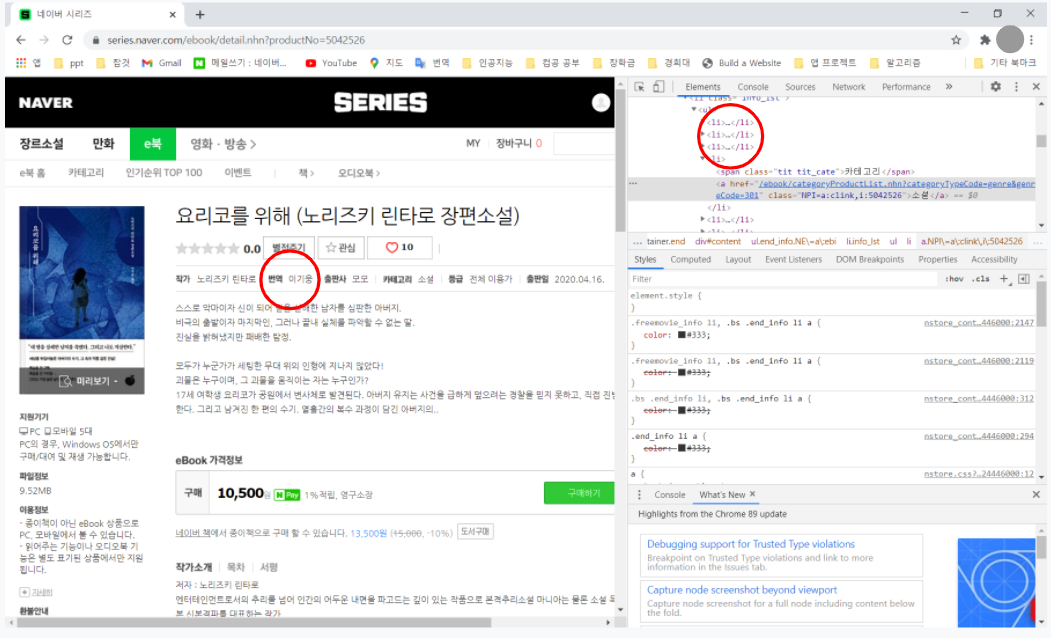
if(category_name not in dic):
dic[category_name] = 1
else:
dic[category_name]+=1
카테고리 이름이 딕셔너리에서 key로써 존재하지 않을 경우 value를 1로 하여 추가하고 존재할 경우 value를 1 증가시켜줌으로써 카테고리를 카운팅해주었다.
except:
if("19" not in dic):
dic["19"] = 1
else:
dic["19"]+=1
크롤링하는 책이 19세 이상 이용가의 책인 경우에는 로그인을 하지 않았을 경우 오류가 발생할 수 있으므로 try, except 구문을 사용하였고 19세 카테고리를 따로 만들어 저장했다.
for key, value in dic.items():
print(key, value)
마지막으로 딕셔너리에 저장된 카테고리의 종류와 빈도수를 출력하여 아래와 같은 결과를 얻었다.

이로써 현재 네이버 e북의 Top100 중 경제/경영에 관련된 책 36권으로 가장 많고 인문 관련 책이 20권, 자기계발 서적이 10권으로 그 다음 순위를 차지함을 확인할 수 있었다.
'개인공부 > 데이터 사이언스' 카테고리의 다른 글
| 로지스틱 회귀 (0) | 2022.03.14 |
|---|---|
| 최근접 이웃(K-Nearest Neighbor) 알고리즘을 이용한 종양 판별 모델 만들기 (0) | 2021.10.03 |
| 신뢰도 높은 리뷰 탐색 프로젝트(파이어베이스, 파이썬) (0) | 2021.03.23 |
| Selenium을 이용한 미세먼지 크롤러 만들기(2) (0) | 2021.03.18 |
| Selenium을 이용한 미세먼지 크롤러 만들기(1) (0) | 2021.03.18 |