
최적화의 기술: 모멘텀부터 배치 정규화까지
딥러닝 모델을 학습시키다 보면 예상치 못한 문제들을 만나게 된다. 손실 함수를 최소화하는 과정이 생각보다 순탄하지 않다. 마치 산을 오르는데 안개가 자욱하고, 바람이 사방에서 불어대고, 발밑의 경사는 고르지 않은 것과 같다. 오늘은 이런 험난한 여정을 조금이라도 수월하게 만들어주는 몇 가지 기법들에 대해 이야기해보려 한다.
잡음과의 싸움: 모멘텀의 등장
미니배치로 학습할 때 근본적인 문제가 하나 있다. 전체 데이터가 아닌 일부 샘플만으로 그래디언트를 추정하기 때문에 항상 잡음이 섞인다는 점이다. 원래는 정확히 북쪽으로 가야 하는데, 어떤 순간에는 북동쪽을 가리키고, 또 어떤 순간에는 북서쪽을 가리킨다. 이렇게 들쭉날쭉한 방향으로 업데이트되다 보면 수렴 속도가 매우 느려진다. 직선으로 가면 10걸음이면 될 것을 지그재그로 가느라 50걸음을 걷는 셈이다.
이 문제를 해결하기 위해 등장한 것이 모멘텀이다. 모멘텀의 아이디어는 놀랍도록 단순하면서도 강력하다. 과거의 그래디언트를 버리지 않고 계속 쌓아간다는 것이다. 마치 부스터를 단 것처럼, 과거에 움직였던 방향의 힘을 받아 현재의 잡음을 극복하고 원래 가야 할 방향으로 쭉 나아간다.
구체적으로 어떻게 작동할까? 현재 위치에서 그래디언트 g1이 계산됐다고 하자. 동시에 과거 그래디언트의 누적인 v가 있다. 모멘텀은 이 둘을 적절히 섞는다. v를 알파만큼 감쇠시키고 현재 그래디언트를 더해서 새로운 v를 만든다. 그리고 이 v로 파라미터를 업데이트한다. 과거의 관성이 현재의 흔들림을 잡아주는 것이다.
이 방법의 또 다른 장점은 궤적을 부드럽게 만든다는 점이다. 급격하게 꺾이는 대신 완만한 곡선을 그리며 최적점으로 향한다. 알파 값은 보통 0.5에서 0.9 사이로 설정하는데, 이를 할인율이라고 부른다. 과거 그래디언트를 약간 할인해서 현재와 섞는다는 의미다.
모멘텀은 세 가지 긍정적 효과를 가져온다. 첫째, 잡음으로 인한 불규칙한 업데이트를 완화한다. 둘째, 오버슈팅 현상을 누그러뜨린다. 셋째, 로컬 미니멈을 탈출할 수 있는 힘을 준다. 특히 세 번째가 흥미롭다. 로컬 미니멈에 빠지면 그래디언트가 0이 되어 더 이상 움직일 수 없다. 하지만 모멘텀이 있으면 과거에 쌓인 속도 벡터 덕분에 그 골짜기를 빠져나와 더 좋은 곳으로 갈 수 있다.
네스테로프의 예견
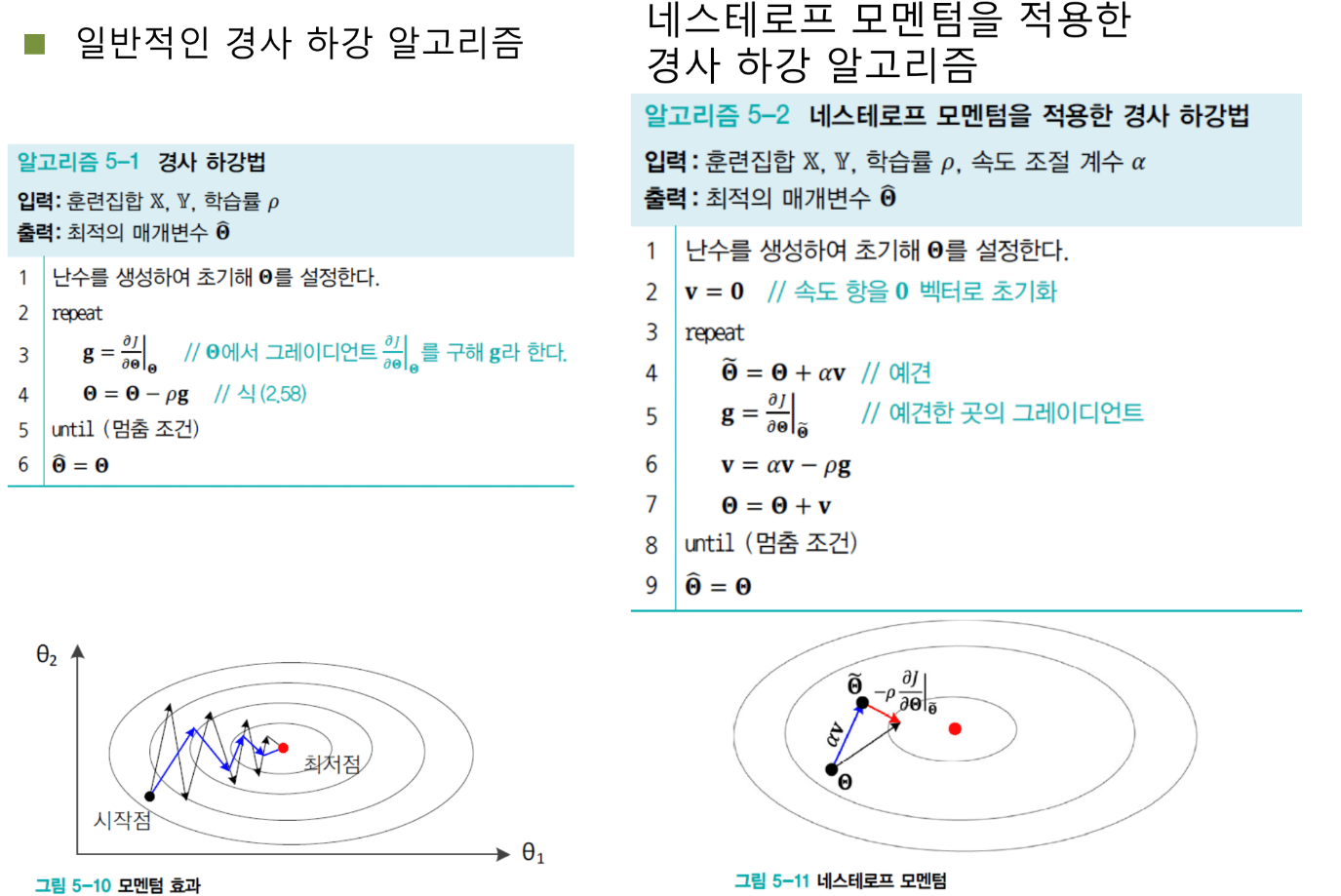
모멘텀이 좋긴 한데, 조금 아쉬운 점이 있다. 현재 위치에서 그래디언트를 구한다는 것이다. 그런데 생각해보면, 우리는 이미 과거의 v 벡터를 가지고 있다. 그렇다면 v 방향으로 먼저 가보고, 거기서 그래디언트를 구하면 어떨까? 이것이 네스테로프 모멘텀의 아이디어다.
축구에 비유하면 스루패스와 같다. 패스를 받을 선수가 지금 있는 위치가 아니라, 그 선수가 달려갈 미래의 위치를 예견해서 미리 공을 차는 것이다. 네스테로프 모멘텀도 마찬가지다. v로 파라미터를 먼저 업데이트하고, 그 '예견된' 위치에서 그래디언트를 구해서 v와 합친다. 이렇게 하면 궤적이 더욱 부드러워지고 더 좋은 로컬 미니멈에 도달할 확률이 높아진다.
오버슈팅의 비밀
모멘텀 이야기를 하다 보니 계속 오버슈팅이라는 말이 나온다. 오버슈팅은 대체 무엇이고 왜 발생할까?
간단한 예를 들어보자. 2차원 로스 랜드스케이프가 있다. 하나는 가중치 w 방향, 하나는 바이어스 b 방향이다. 이상적으로는 로스 랜드스케이프가 동그란 그릇 모양이면 좋다. 그러면 어디서 시작하든 중심을 향해 곧장 굴러떨어진다. 하지만 실제로는 타원 모양이거나 더 심하게 찌그러진 경우가 많다.
타원이 길쭉하다는 것은 한 방향으로는 경사가 완만하고, 다른 방향으로는 가파르다는 뜻이다. w 방향으로는 기울기가 -1 정도로 작은데, b 방향으로는 -10처럼 크다고 하자. 그러면 어떤 일이 벌어질까? 실제로 가야 할 방향은 w 방향으로 길게 가는 것인데, 그래디언트는 b 방향으로 크게 발생한다. 결과적으로 정반대 방향으로 힘이 작용해서 지그재그로 튕기게 된다. 이것이 오버슈팅이다.
왜 이런 일이 벌어질까? 각 파라미터가 로스에 미치는 영향이 다르기 때문이다. 어떤 가중치는 1 바꿔도 로스가 거의 안 변한다. 어떤 가중치는 1 바꾸면 로스가 100 떨어진다. 민감도가 다른 것이다. 로스 랜드스케이프의 모양은 이 민감도 차이를 반영한다. 민감한 방향은 가파르고, 둔감한 방향은 완만하다.
적응적 학습률: 각자에게 맞는 속도를
오버슈팅 문제를 해결하는 또 다른 접근이 있다. 바로 적응적 학습률이다. 기존의 학습률은 모든 가중치에 똑같이 적용됐다. 0.01이면 모든 그래디언트에 0.01을 곱한다. 하지만 가중치마다 민감도가 다른데 왜 같은 학습률을 써야 할까?
적응적 학습률의 철학은 이렇다. 그래디언트가 큰 가중치는 학습률을 작게 주고, 그래디언트가 작은 가중치는 학습률을 크게 줘서, 결과적으로 모든 그래디언트가 비슷한 크기가 되게 하자. 이렇게 하면 찌그러진 타원이 동그란 원에 가까워진다. 오버슈팅이 사라지고 어디서 시작하든 곧바로 최적점으로 수렴한다.
AdaGrad가 이를 구현한 첫 번째 방법이다. r이라는 벡터를 도입하는데, 이것은 그래디언트 제곱의 누적이다. 그래디언트를 구할 때마다 그 제곱을 r에 더한다. 그리고 실제 업데이트할 때는 학습률을 √r로 나눈다. 그래디언트가 컸던 차원은 r이 크니까 학습률이 작아지고, 그래디언트가 작았던 차원은 r이 작으니까 학습률이 커진다. 완벽하다.
하지만 치명적인 문제가 있었다. r은 계속 누적된다. 제곱 값이 계속 더해지니 r은 무한정 커진다. 학습 초반에는 괜찮은데, 나중에 가면 r이 너무 커져서 학습률이 거의 0에 가까워진다. 학습이 멈춰버리는 것이다.

RMSProp: 과거에 할인을 적용하다
AdaGrad의 문제를 해결한 것이 RMSProp이다. 아이디어는 간단하다. 과거의 r에 할인율을 적용하는 것이다. 모멘텀에서 v에 알파를 곱했던 것처럼, r에도 알파를 곱한다. 그리고 현재 그래디언트 제곱을 (1-알파) 비율로 섞는다. 가중 평균이다.
이렇게 하면 r이 무한정 커지지 않는다. 최근 그래디언트의 영향이 크고, 오래된 그래디언트의 영향은 점차 사라진다. 학습 후반에도 적응적 학습률이 제대로 작동한다.

Adam: 두 세계의 결합
모멘텀은 좋다. 적응적 학습률도 좋다. 그렇다면 둘을 합치면 어떨까? 이것이 Adam의 탄생 배경이다. Adam은 Adaptive Moment Estimation의 약자인데, 적응적 학습률의 Ada와 모멘텀의 M을 합친 이름으로 보인다. 누군가는 이 이름을 짓고 "아담이네, 완벽해!"라고 생각했을지도 모른다.
Adam은 두 개의 벡터를 유지한다. v는 모멘텀을 위한 그래디언트 누적, r은 적응적 학습률을 위한 제곱 누적이다. 업데이트할 때는 v를 사용하되, 학습률을 √r로 나눈다. 모멘텀의 방향성과 적응적 학습률의 안정성을 동시에 얻는 것이다.
실험 결과를 보면 Adam의 우수성이 확연히 드러난다. 복잡한 로스 랜드스케이프에서 일반 SGD는 느리게 기어간다. 모멘텀은 빠르지만 튕긴다. RMSProp도 괜찮다. 하지만 Adam은 가장 빠르고 안정적으로 최적점에 도달한다. 그래서 현재 Adam은 딥러닝에서 가장 널리 쓰이는 최적화 알고리즘이 되었다.
Adam의 작은 비밀
Adam 알고리즘을 자세히 보면 이상한 부분이 있다. v와 r을 업데이트한 후 이상한 보정을 한다. v를 (1-α^t)로 나누고, r도 마찬가지로 나눈다. 왜 이런 짓을 할까?
이유는 초기화 때문이다. v와 r은 0에서 시작한다. 하지만 0에서 시작하면 초반에 모멘텀과 적응적 학습률 효과를 제대로 누리지 못한다. 축적된 에너지가 없기 때문이다. 그래서 인위적으로 펌핑해준다. 알파가 0.9라면 첫 번째 스텝에서 보정 계수는 약 10이 된다. v를 10배로 뻥튀기하는 것이다. 그러다가 t가 커지면 보정 계수는 1로 수렴한다.
이것은 일종의 전이 상태 관리다. 컴퓨터를 켤 때 바로 윈도우가 뜨지 않고 BIOS를 불러오고 OS를 램에 올리는 과정을 거치듯, Adam도 처음 몇 스텝은 '워밍업' 단계다. 이 단계를 빨리 지나가기 위해 v와 r을 부스팅하는 것이다.
안장점의 문제
최적화에서 또 하나 중요한 문제가 안장점이다. Saddle Point, 말 안장처럼 생긴 점이다. 어떤 방향에서는 아래로 볼록하고, 다른 방향에서는 위로 볼록하다. 정확히 그 중간 지점에서는 그래디언트가 거의 0이다.
일반 SGD는 안장점에서 꼼짝 못한다. 그래디언트가 없으니 업데이트할 힘이 없다. 하지만 모멘텀이나 적응적 학습률은 안장점을 빠르게 탈출한다. 모멘텀은 과거의 속도로, 적응적 학습률은 작은 그래디언트를 증폭시켜서 탈출한다. 실제 시뮬레이션을 보면 SGD는 안장점에서 오래 머무는 반면, 다른 방법들은 거의 멈추지 않고 통과한다.
활성화 함수의 진화
최적화 알고리즘만큼이나 중요한 것이 활성화 함수다. 활성화 함수의 역사는 곧 Vanishing Gradient와의 싸움의 역사다.
초창기에는 계단 함수를 썼다. 퍼셉트론의 시대다. 하지만 계단 함수는 미분이 불가능하다. 그 다음 Sigmoid와 tanh가 등장했다. 부드럽고 미분 가능하지만, 양 극단에서 그래디언트가 0에 가까워지는 문제가 있었다. 깊은 네트워크에서는 치명적이다.
그래서 등장한 것이 ReLU다. Rectified Linear Unit. 양수면 그대로 통과, 음수면 0. 놀랍도록 단순하지만 효과적이다. 양수 영역에서는 그래디언트가 항상 1이니 Vanishing Gradient 문제가 없다. 계산도 빠르다. 혁명적이었다.
ReLU도 완벽하지는 않다. 음수 영역을 모두 0으로 만들면 정보 손실이 크다. 그래서 Leaky ReLU가 나왔다. 음수에도 작은 기울기(0.01 정도)를 준다. 정보를 조금이라도 보존하자는 것이다. 더 나아가 PReLU는 이 기울기를 학습 가능한 파라미터로 만들었다. 레이어마다 최적의 기울기를 자동으로 찾는다.
배치 정규화: 게임 체인저
2015년, 딥러닝 역사에서 획기적인 논문이 나왔다. Batch Normalization. 나는 MIT의 저명한 교수가 "나도 이런 연구를 하고 싶었다. Simple yet powerful하지 않나"라고 감탄하는 것을 직접 들은 적이 있다. 배치 정규화는 정말 단순하면서도 강력하다.
배치 정규화가 해결하려는 문제는 공변량 시프트다. Covariate Shift. 무슨 말일까? 학습 초기에는 가중치를 잘 초기화해서 각 층의 출력이 평균 0, 분산 1인 정규분포를 따르게 할 수 있다. 하지만 학습이 진행되면서 가중치가 업데이트되면 분포가 틀어진다. 평균이 0에서 1로, 다시 10으로, 100으로 계속 밀려난다. 분산도 마찬가지다. 네트워크가 깊어질수록 이 현상은 심해진다.
문제는 이렇게 분포가 계속 변하면 학습이 불안정해진다는 것이다. 각 층은 매번 다른 분포의 입력을 받으니 적응하기 어렵다. 심한 경우 학습이 아예 멈춰버린다.
배치 정규화의 해결책은 직관적이다. 각 층마다 정규화를 한다. 출력의 평균을 빼고 표준편차로 나눈다. 그러면 다시 평균 0, 분산 1인 표준 정규분포가 된다. 분포를 강제로 고정하는 것이다.
하지만 여기서 끝이 아니다. 배치 정규화의 천재성은 다음 단계에 있다. 평균 0, 분산 1이 항상 최적일까? 아닐 수도 있다. 어떤 층은 평균 1, 분산 2가 더 좋을 수도 있다. 그래서 γ(감마)와 β(베타)라는 학습 가능한 파라미터를 도입한다. 정규화된 값에 γ를 곱하고 β를 더한다. γ는 스케일을, β는 시프트를 조절한다. 각 층이 자신에게 최적인 분포를 스스로 학습하는 것이다.
배치 정규화의 마법 같은 효과들
배치 정규화를 적용하면 여러 놀라운 효과가 나타난다.
첫째, 가중치 초기화에 덜 민감해진다. 초기화를 잘못해도 배치 정규화가 분포를 바로잡아준다. 두 번째 층부터는 이미 정규화된 입력을 받으니 문제없다.
둘째, 학습률을 크게 해도 된다. 분포가 안정적이니 큰 스텝으로 업데이트해도 발산하지 않는다. 수렴 속도가 빨라진다.
셋째, 가장 놀라운 것은 Sigmoid를 써도 된다는 점이다. Sigmoid의 문제는 큰 입력에서 그래디언트가 0이 되는 것이었다. 하지만 배치 정규화로 입력을 항상 0 근처로 유지하면 Sigmoid도 그래디언트를 잘 만들어낸다. 깊은 네트워크에서도 Sigmoid를 쓸 수 있게 된 것이다.
넷째, 규제 효과를 제공한다. Dropout을 쓰지 않아도 일반화 성능이 좋다. 미니배치마다 조금씩 다른 평균과 분산을 사용하니 일종의 노이즈 주입 효과가 있다.
배치 정규화의 실제 구현
실전에서는 어떻게 쓸까? Convolution → Batch Normalization → ReLU 순서가 기본이다. 이 세 개가 하나의 세트다. 실험 결과 Convolution 직후에 배치 정규화를 적용하는 것이 ReLU 뒤에 적용하는 것보다 훨씬 좋았다.
배치 정규화는 미니배치의 평균과 분산을 사용한다. 전체 데이터셋으로 하면 비용이 너무 크다. 미니배치로 근사해도 충분히 효과적이다. 하지만 추론 시에는 어떻게 할까? 추론할 때는 샘플이 하나씩 들어올 수도 있다. 배치가 없다.
해결책은 학습 중에 전체 데이터셋의 평균과 분산을 이동 평균으로 추적하는 것이다. 그리고 추론 시에는 이 값을 사용한다. 실제로는 정규화와 선형 변환을 하나의 식으로 합칠 수 있어서 추론이 매우 빠르다.
CNN에서는 조금 다르다. 배치 정규화의 단위가 중요하다. 같은 채널끼리 묶어서 정규화한다. 예를 들어 배치 크기가 32이고 채널이 64개라면, 각 채널마다 32개 샘플의 모든 위치에서 평균과 분산을 구한다. 채널 인덱스별로 64개의 독립적인 배치 정규화가 수행되는 것이다.
정규화의 다양한 변주들
배치 정규화는 미니배치가 필요하다. 하지만 배치를 쓸 수 없는 상황도 있다. 샘플이 너무 커서 배치 크기를 2로밖에 못하는 경우, 또는 배치를 쓰지 않는 것이 더 유리한 경우가 있다.
그래서 다른 정규화 방법들이 나왔다. Layer Normalization은 하나의 샘플에 대해 모든 채널을 통틀어 정규화한다. Instance Normalization은 샘플 하나의 채널 하나씩 정규화한다. Group Normalization은 중간이다. 채널들을 몇 개의 그룹으로 나누고 그룹별로 정규화한다.
Instance Norm은 채널 하나만 정규화하니 통계가 불안정하다. 값이 몇 개 없어서 평균과 분산이 흔들린다. Group Norm은 여러 채널을 묶어서 안정성을 높인다. 각각 장단점이 있고, 문제에 따라 선택한다.
고주파와 정규화
흥미로운 질문이 나왔다. "정규화를 하면 미세한 고주파 성분이 사라지는 거 아닌가요?" 정규화는 값의 범위를 줄인다. 큰 값과 작은 값의 차이를 좁힌다. 그렇다면 세밀한 디테일이 뭉개지는 것 아닐까?
중요한 통찰이다. 하지만 순서는 보존된다. 가장 큰 값은 정규화해도 여전히 가장 크다. 두 번째로 큰 값도 여전히 두 번째다. 신호의 구조, 패턴은 유지된다. 단지 스케일과 평균이 바뀔 뿐이다.
비유하자면 화씨와 섭씨 같은 것이다. 온도를 화씨로 재든 섭씨로 재든 "오늘이 어제보다 덥다"는 사실은 변하지 않는다. 정규화는 측정 단위를 바꾸는 것이지, 현상 자체를 바꾸는 게 아니다.
하지만 생성 AI에서는 다른 문제가 있다. 생성된 이미지를 보면 너무 깨끗하다. 실제 사진은 모공, 주름, 센서 노이즈 등 자잘한 고주파 성분이 많다. 하지만 생성 이미지는 부드럽다. 고주파가 부족하다. 이것은 정규화 때문이 아니라 생성 모델 자체의 한계다. 고주파를 생성하는 것은 여전히 어려운 문제다.
오버슈팅과 발산
마지막으로 오버슈팅과 발산의 관계를 정리해보자. 오버슈팅이 심하면 발산할 수도 있다. 하지만 모든 오버슈팅이 발산으로 이어지는 것은 아니다.
오버슈팅은 예상 경로를 벗어나는 것이다. 주식으로 치면 적정 가치보다 훨씬 높게 오르는 거품이다. 최적화에서는 최적점을 지나쳐서 반대편으로 튕기는 현상이다. 로스 랜드스케이프가 V자 모양이면 왔다갔다 진동한다. 깊고 가파른 골짜기라면 들어갔다 나왔다를 반복할 수도 있다.
핵심은 이것이다. 타원이 심하게 찌그러질수록 오버슈팅이 심하다. 모멘텀과 적응적 학습률은 타원을 원에 가깝게 만들어 오버슈팅을 줄인다. Adam은 둘을 결합해 가장 안정적인 수렴을 달성한다.
정리하며
최적화는 예술이자 과학이다. 이론적으로 분석할 수 있지만, 실전에서는 직관과 경험이 필요하다. 모멘텀은 과거의 관성을 활용해 잡음을 극복한다. 적응적 학습률은 각 파라미터에 맞는 속도를 준다. Adam은 둘을 결합해 가장 강력한 최적화 도구가 되었다.
활성화 함수는 ReLU가 표준이 되었다. 단순하지만 Vanishing Gradient를 해결한다. 배치 정규화는 게임 체인저였다. 분포를 안정화해 학습을 획기적으로 개선했다. 다양한 정규화 변형들이 각자의 쓰임새를 가진다.
이 모든 기법들의 공통점은 무엇일까? 학습을 안정화하고 가속화한다는 것이다. 그래디언트가 잘 흐르게 하고, 발산을 막고, 빠르게 수렴하게 한다. 딥러닝의 성공은 이런 섬세한 최적화 기법들 위에 세워졌다.
하지만 여전히 많은 것이 미스터리다. 왜 Adam이 그렇게 잘 작동하는지 완전히 이해하지 못한다. 배치 정규화의 성공 이유도 처음 생각과는 다를 수 있다. 우리는 계속 실험하고, 관찰하고, 배운다. 그것이 딥러닝 연구의 흥미로운 점이다. 이론과 실천이 만나고, 때로는 놀라운 발견이 기다리고 있다.