레이블 없는 세계에서 패턴 찾기: 비지도 학습 이야기
프롤로그: 유튜브는 어떻게 당신을 알까?
유튜브를 켜면 마치 나를 아는 듯한 추천 영상들이 펼쳐진다. 테니스를 좋아하는 사람에게는 테니스 하이라이트가, 요리에 관심 있는 사람에게는 맛집 탐방이 나타난다. 심지어 같은 집에 사는 부부도 완전히 다른 콘텐츠를 받는다. 한 사람은 스포츠와 기술 영상을, 다른 사람은 예술과 동물 영상을 본다.
이 마법 같은 일은 어떻게 가능할까? 비밀은 **비지도 학습(Unsupervised Learning)**에 있다. 시스템은 당신이 무엇을 좋아하는지 명시적으로 말하지 않아도, 당신의 시청 패턴을 전 세계 수백만 사용자의 패턴과 비교해 유사한 사람들의 그룹을 찾아낸다. 그리고 그 그룹이 소비하는 콘텐츠를 당신에게 추천한다.
이것이 레이블 없이도 의미 있는 정보를 발견하는 비지도 학습의 힘이다.
지도와 비지도: 두 세계의 차이
지도학습은 선생님이 있는 교실과 같다. 입력 X(이미지)와 정답 Y(레이블)가 모두 주어진다. "이것은 고양이야"라고 알려주며 가르친다. 학습의 목표는 명확하다: X를 Y로 매핑하는 함수 f를 배우는 것.
하지만 비지도학습은 다르다. X만 주어지고 Y는 없다. 이미지는 잔뜩 있지만 그것이 무엇인지 아무도 알려주지 않는다. 마치 지도 없이 낯선 도시를 탐험하는 것과 같다. 하지만 놀랍게도, 이런 상황에서도 우리는 많은 것을 배울 수 있다.
비지도학습의 응용은 생각보다 광범위하다:
맞춤형 광고와 추천 시스템: 유사한 사용자들을 그룹으로 묶어 개인화된 경험을 제공한다.
차원 축소와 데이터 압축: 784차원의 이미지 정보를 10차원으로 압축하면서도 핵심 정보는 보존한다. 유튜브가 적은 데이터로 고품질 영상을 전송하는 비결이다.
데이터 가시화: 고차원 데이터를 2차원이나 3차원으로 변환해 사람이 볼 수 있게 만든다. 마치 복잡한 현상을 지도로 그리는 것과 같다.
생성 모델: Variational Autoencoder(VAE) 같은 모델은 입력을 압축했다가 복원한다. 이 과정에서 중요한 특징만 병목(bottleneck)을 통과하게 되고, 이 압축된 표현을 조작하면 새로운 이미지를 생성할 수 있다.
준지도학습: 현실의 타협
현실은 종종 흑백논리보다 복잡하다. 데이터는 많은데 레이블링할 시간은 없는 상황을 상상해보자.
예를 들어 "냉장고를 부탁해" 프로젝트를 만든다고 하자. 냉장고 안의 재료를 인식해 레시피를 추천하는 앱이다. 구글에서 야채, 마요네즈, 계란 이미지를 100만 장씩 다운받았다. 총 1,000만 장의 이미지가 있다.
문제는 레이블링이다. 하루 최대 2천 장을 처리할 수 있다고 치자. 열흘 동안 열심히 해도 2만 장뿐이다. 998만 장은 여전히 레이블이 없다.
이때 **준지도학습(Semi-supervised Learning)**이 등장한다. 핵심 가정은 이렇다: 레이블이 없는 샘플들도 특징 공간에서 군집을 이룬다. 그리고 같은 군집에 속한 샘플들은 같은 클래스일 확률이 높다. 따라서 소수의 레이블된 데이터와 다수의 레이블 없는 데이터를 함께 사용하면, 모든 데이터에 레이블이 있는 것과 유사한 성능을 낼 수 있다.
두 가지 사전 지식: 세상을 이해하는 렌즈
비지도학습에서는 데이터 자체가 빈약하다(레이블이 없으니까). 따라서 **사전 지식(Prior Knowledge)**이 더욱 중요해진다. 이는 데이터와 무관하게 세상의 일반적인 규칙을 의미한다.
비지도학습은 특히 두 가지 사전 지식에 의존한다:
1. 매니폴드 가정 (Manifold Hypothesis)
MNIST 데이터는 784차원 특징 공간에 살고 있다. 28×28 픽셀이니까. 이 거대한 공간에 6만 장의 샘플이 희소하게 분포한다.
만약 이 샘플들이 무작위로 흩어져 있다면? 일반화는 불가능하다. 하지만 다행히도 그렇지 않다. 데이터는 특정한 **매니폴드(다양체)**에 모여 있다.
매니폴드는 고차원 공간 속의 저차원 구조다. 마치 3차원 공간에 떠 있는 2차원 곡면처럼. 784차원 공간 전체가 의미 있는 것이 아니라, 그 안의 특정한 저차원 구조에서만 샘플이 발생한다.
비유하자면 이렇다: 서울이라는 거대한 도시(고차원 공간)가 있지만, 사람들은 주로 지하철 노선(저차원 매니폴드)을 따라 움직인다. 전체 도시를 다 알 필요 없이 지하철 노선만 알면 대부분의 이동을 이해할 수 있다.
이 매니폴드만 잘 학습하면, 트레이닝 샘플도 테스트 샘플도 모두 이 매니폴드에서 나오므로 일반화 성능이 보장된다.
2. 매끄러운 가정 (Smoothness Assumption)
매니폴드 가정의 확장판이다. 샘플들이 매니폴드에 모여 있을 뿐만 아니라, 매니폴드 상에서 부드럽게 변화한다는 가정이다.
예를 들어 숫자 1의 이미지 매니폴드를 생각해보자:
- X축 방향으로 이동하면: 1의 크기가 점점 커진다
- Y축 방향으로 이동하면: 1의 각도가 5도, 10도, 15도... 점점 기울어진다
무작위로 점프하는 것이 아니라, 의미론적으로 연속적인 변화가 일어난다. 이 매끄러운 변화 패턴을 발견하면, 레이블 없이도 데이터의 구조를 이해할 수 있다.
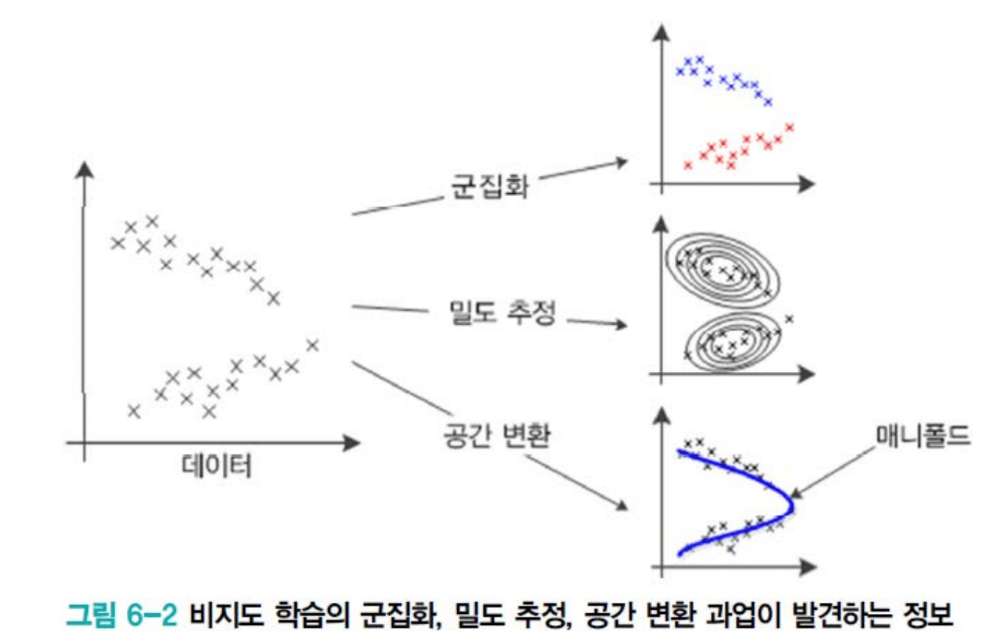
세 가지 과업: 비지도학습이 하는 일
비지도학습의 일반적인 과업은 세 가지로 나뉜다:
1. 군집화 (Clustering): 유사한 샘플들을 같은 그룹으로 묶는다. 유튜브 사용자를 "경제 콘텐츠 그룹", "음악 콘텐츠 그룹"으로 나누는 것. 영상 분할에서는 픽셀들을 군집화해 "사람", "책상", "의자" 영역을 찾아낸다.
2. 밀도 추정 (Density Estimation): 샘플들이 원래 어떤 확률분포 P(X)로부터 왔는지 추정한다. 주사위를 던져 3, 5, 6이 나왔다면, 이 결과로부터 주사위의 확률분포를 역추정하는 것과 같다. P(X)를 알면 무한대의 새로운 샘플을 생성할 수 있다.
3. 공간 변환 (Space Transformation): 고차원 특징 공간을 저차원으로 변환한다. 키와 몸무게라는 2차원 데이터에서 1차원 매니폴드를 찾아내면, 더 본질적인 특징으로 데이터를 표현할 수 있다.
흥미롭게도 이 세 가지는 사실 매우 밀접하게 연결되어 있다. 모두 매니폴드와 매끄러운 가정에 기반하며, 쓰임새만 다를 뿐 본질적 메커니즘은 유사하다.
K-means: 평균의 힘으로 군집 찾기
군집화의 가장 대표적인 알고리즘이 K-means다. 놀랍도록 단순하지만 매우 효과적이다. 여러분이 태어나기 훨씬 전에 만들어졌지만, 지금도 최신 딥러닝 논문에서 활발히 사용된다.
알고리즘의 원리
K-means는 이름에서 알 수 있듯 "K개의 평균"을 찾는다:
입력:
- 훈련 집합 X (레이블 Y는 없음!)
- 군집 개수 k (hyperparameter)
출력:
- 각 샘플의 군집 소속: x₁은 [1,0], x₂는 [0,1] 등
과정:
- 초기화: k개의 군집 중심 z₁, z₂, ..., zₖ를 랜덤하게 또는 균등하게 배치한다.
- 반복:
- 할당 단계: 각 샘플 x를 가장 가까운 군집 중심에 할당한다.
- 두 군집 중심을 연결하는 직선의 수직 이등분선을 그으면, 이 선을 기준으로 위는 z₁, 아래는 z₂에 가깝다.
- 업데이트 단계: 군집의 중심을 재계산한다.
- 파란색에 할당된 60개 샘플의 X좌표 평균, Y좌표 평균을 구해 z₁을 업데이트
- 빨간색에 할당된 40개 샘플의 평균으로 z₂를 업데이트
- 할당 단계: 각 샘플 x를 가장 가까운 군집 중심에 할당한다.
- 종료 조건: 군집 중심이 더 이상 움직이지 않거나, 샘플의 소속이 바뀌지 않으면 종료

왜 작동하는가?
반복할수록 군집 중심이 진짜 군집의 중심으로 수렴하는 것이 수학적으로 보장되어 있다. 목적 함수를 다음과 같이 쓸 수 있다:
J = Σᵢ Σₖ aᵢₖ · dist(xᵢ, zₖ)
여기서:
- aᵢₖ: 샘플 i가 군집 k에 할당되면 1, 아니면 0
- dist(xᵢ, zₖ): 샘플 i와 군집 중심 k의 거리
Z가 고정되어 있을 때: 각 샘플을 가장 가까운 중심에 할당하면 J가 최소화된다.
A가 고정되어 있을 때: 각 군집에 속한 샘플들의 평균으로 중심을 이동하면 J가 최소화된다.
따라서 두 단계를 번갈아 수행하면, 매 반복마다 J가 감소하거나 동일하다. 절대 증가하지 않는다. 이것이 K-means의 수렴 보장이다.

K를 결정하는 문제
가장 큰 도전은 군집 개수 k를 정하는 것이다. 같은 데이터를 봐도:
- 어떤 사람은 k=2 (위와 아래 두 그룹)
- 어떤 사람은 k=3 (조금 더 세분화)
- 어떤 사람은 k=4 (더욱 세밀하게)
정답은 없다. 응용과 요구사항에 따라 적절히 선택해야 하는 hyperparameter다.
k가 너무 작으면: 하나의 군집으로 전체를 표현해 의미 있는 정보가 희석된다. k가 너무 크면: 과도하게 세분화되어 본질적인 패턴을 놓친다.
평균의 함정: Outlier 문제
평균에는 치명적인 약점이 있다. outlier에 취약하다는 것.
강의실에서 5명의 키를 측정하는데, 우연히 그중 한 명이 키 218cm의 최홍만 선수였다고 상상해보자. 평균 키가 갑자기 10cm 올라간다. 이 평균이 대표성이 있을까?
군집화에서도 마찬가지다:
실제 군집은 여기 모여있다: ●●●●●
하지만 멀리 outlier가 하나: ●●●●● -------------------- ●
평균을 구하면 군집 중심이 outlier에게 끌려가 오른쪽으로 시프트된다. 이것이 평균 함정이다.
K-medoids: 대표자를 뽑자
이 문제를 해결하는 방법이 K-medoids다. 평균을 구하는 대신, 실제 샘플 중 하나를 군집의 중심으로 선택한다.
어떤 샘플을 선택해야 할까? 가장 무난한 사람을 뽑으면 된다.
대한민국에서 비유하자면 대전과 같다. 대전에서는 어디를 가든 대략 2시간이면 도달한다. 중심에 위치하기 때문이다.
수학적으로는: 다른 모든 샘플들과의 거리 합이 최소인 샘플을 선택한다.
Σⱼ dist(xᵢ, xⱼ) 를 최소화하는 xᵢ를 군집 중심으로
장점: Outlier에 강건하다. 한 샘플이 아무리 멀리 떨어져 있어도, 다수의 샘플이 모여 있는 곳의 샘플이 선택된다.
단점: 계산 복잡도가 O(n²)이다. 각 샘플마다 다른 모든 샘플과의 거리를 계산해야 하므로. 평균은 O(n)인 것과 대조적이다.
RANSAC과 거리 메트릭
학생이 좋은 질문을 했다: "RANSAC으로 outlier를 제거하면 어떨까요?"
RANSAC(Random Sample Consensus)은 통계적으로 안정한 샘플을 얻는 방법이다. 파노라마 이미지를 만들 때, 여러 이미지의 같은 위치를 매칭하는 correspondence matching에서 사용한다.
카메라가 살짝 움직이면서 찍었기 때문에, 어떤 매칭은 정확하고 어떤 매칭은 부정확하다. RANSAC은 이 부정확한 매칭(outliers)을 효과적으로 제거한다.
군집화에도 적용 가능하지만, 계산 복잡도가 상당히 높다. 또한 대학교 2학년 딥러닝 수업에서 다루기엔 난이도가 있다.
또 다른 접근은 거리 메트릭을 바꾸는 것이다:
- L² norm: outlier에 더 민감 (거리의 제곱이므로)
- L¹ norm (유클리디안): 선형적 페널티
- L⁰·⁵ norm (제곱근): outlier에 덜 민감
- Log distance: 로그를 씌워 outlier 영향 완화
Mahalanobis Distance: 분포를 고려한 거리
더 정교한 방법은 **마할라노비스 거리(Mahalanobis Distance)**를 사용하는 것이다.
유클리디안 거리는 물리적 거리만 본다. 하지만 같은 물리적 거리라도 통계적 의미는 다를 수 있다:
군집 A (표준편차 작음): ●●●●● x₁
군집 B (표준편차 큼): ● ● ● ● ● x₂
평균에서 x₁까지와 평균에서 x₂까지의 물리적 거리가 같다고 하자. 하지만:
- x₁은 군집 A에서 통계적으로 매우 먼 outlier다 (표준편차가 작으니까)
- x₂는 군집 B에서 통계적으로 가까운 정상 샘플이다 (표준편차가 크니까)
마할라노비스 거리는 이를 반영한다:
d_Mahalanobis = (x - μ) / σ
표준편차로 나누어, 분포의 퍼진 정도를 고려한 거리를 계산한다. 이 거리를 사용하면 likelihood를 직접 다룰 수 있고, 통계적으로 더 의미 있는 군집화가 가능하다.
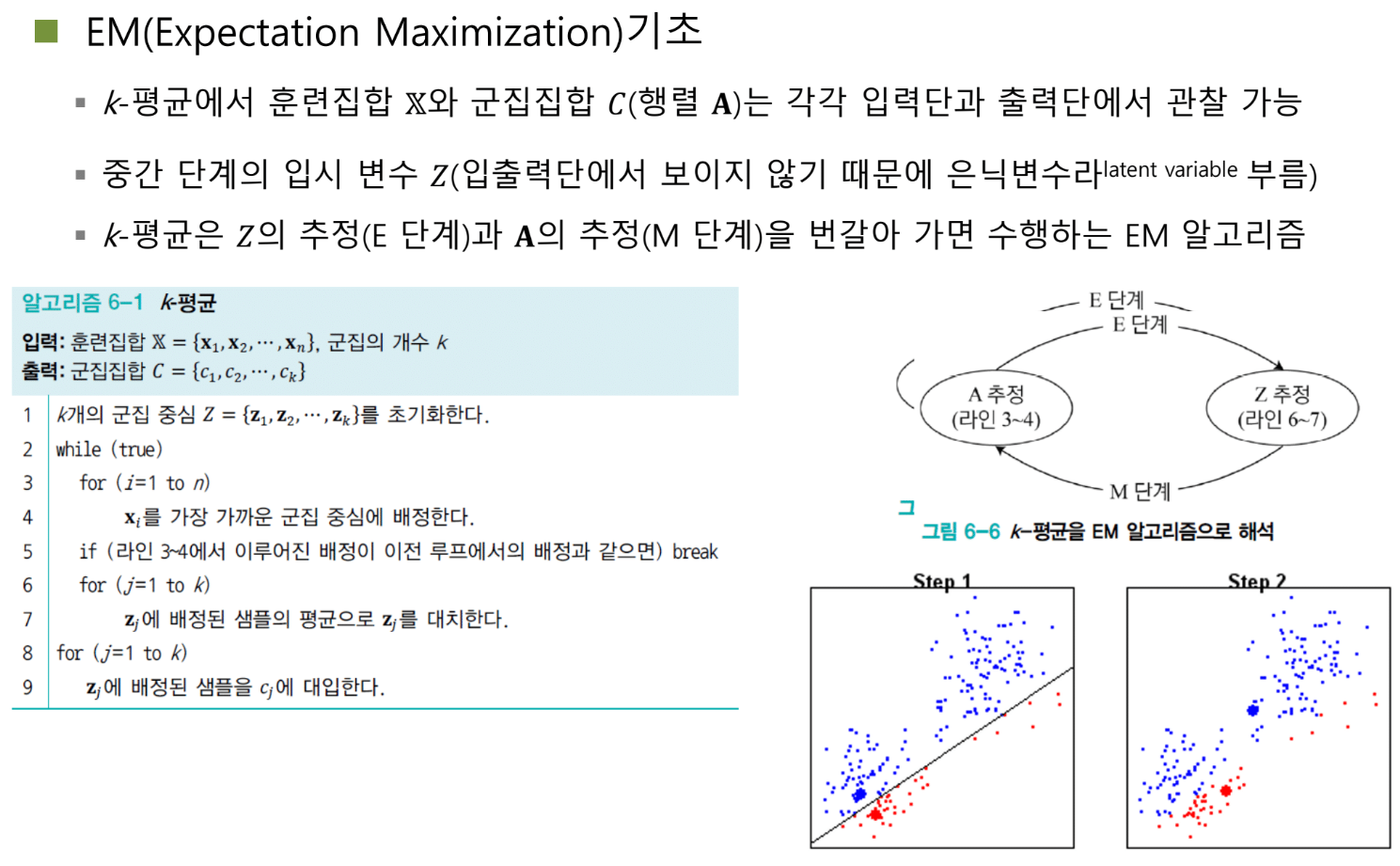
EM 알고리즘: 숨은 친구의 도움
K-means는 사실 더 큰 프레임워크의 한 예시다. 바로 Expectation-Maximization (EM) 알고리즘이다.
EM의 철학
축구에 비유해보자. 내가 슛을 쏘고 싶은데 앞에 수비수들이 막고 있다. 직접 슛을 쏘기 어렵다. 어떻게 할까?
옆에서 빠르게 달려오는 윙 선수에게 패스한다. 그 선수가 슛을 넣는다. 이것이 EM의 아이디어다.
목표를 직접 달성하기 어려울 때, 은닉 변수(hidden variable)라는 중간 매개체를 도입해 간접적으로 목표를 달성한다.
K-means에서:
- 직접 목표: 각 샘플이 어느 군집에 속하는지 알아내기
- 은닉 변수: 군집의 중심 Z
- 전략: Z를 먼저 추정하고, Z를 이용해 군집 소속을 결정하고, 다시 Z를 업데이트하고...
두 단계의 춤
EM은 두 단계를 반복한다:
E-step (Expectation): 은닉 변수를 추정한다.
- K-means에서는 현재 군집 소속을 기반으로 군집 중심 Z를 평균으로 업데이트
M-step (Maximization): 은닉 변수로부터 실제 출력을 얻는다.
- K-means에서는 현재 군집 중심 Z를 기반으로 각 샘플의 군집 소속 A를 결정
- 목적 함수 J를 최소화 = likelihood를 최대화
이 두 단계를 번갈아 수행하면, likelihood의 lower bound가 단조증가한다. 다시 말해:
- iteration을 더 돌렸는데 성능이 나빠지는 일은 절대 없다
- 항상 개선되거나 최소한 동일하다
- 이것이 수학적으로 보장되어 있다
그래서 K-means 시각화를 보면 샘플들이 점점 군집 중심으로 빨려 들어가는 것을 볼 수 있다. 이건 "그냥 그렇게 보여서"가 아니라 수학적으로 보장된 현상이다.
NAS: EM의 현대적 응용
EM은 오래된 기법이지만 여전히 최신 연구에서 활용된다. **Neural Architecture Search (NAS)**가 대표적이다.
NAS의 목표는: 주어진 데이터에 최적인 신경망 구조를 자동으로 찾는 것.
어떤 데이터에는 컨볼루션 레이어 10개가 최적이고, 다른 데이터에는 컨볼루션 2개 + 풀리 커넥티드 2개가 최적일 수 있다. 이 구조를 사람이 일일이 시도하지 않고 알고리즘이 찾아주면 얼마나 좋을까?
NAS의 이중 최적화 문제
NAS에는 두 가지 변수가 있다:
W (가중치): 각 레이어가 학습하는 파라미터 A (아키텍처): 어떤 레이어를 선택할지 결정하는 파라미터
예를 들어 노드 Z₁에서 Z₂로 가는 방법이 여러 가지다:
- 3×3 컨볼루션 (W₁)
- Skip connection (W₂)
- Fully connected (W₃)
- Self-attention (W₄)
- Max pooling (W₅)
각 방법이 선택될 확률이 A = [a₁, a₂, a₃, a₄, a₅]다.
문제: W와 A를 동시에 최적화할 수 없다.
- W가 학습되어야 A를 제대로 선택할 수 있다 (어느 레이어가 좋은지 알려면 학습해봐야)
- A가 결정되어야 W를 학습할 수 있다 (어떤 레이어를 학습할지 정해야)
EM으로 해결하기
이것이 전형적인 bi-optimization (이중 최적화) 문제다. EM으로 해결한다:
- W 고정, A 업데이트: 현재 학습된 가중치로 어떤 레이어가 좋은지 평가
- A 고정, W 업데이트: 선택된 레이어들의 가중치를 학습
이를 반복하면:
- 처음엔 모든 레이어가 10%씩 균등한 확률
- 점점 특정 레이어로 기울어져: 90%, 95%, 98%...
- 최종적으로 한 경로만 남고 나머지는 사라짐
거대한 슈퍼 모델에서 필요 없는 부분을 점진적으로 제거해, 최적의 서브 네트워크를 추출하는 것이다.
이것이 EM의 힘이다. Alternative optimization(대안적 최적화)라고도 부른다. 직접 최적화가 어려울 때, 중간 변수를 도입해 번갈아가며 최적화하는 일반적인 전략이다.
매니폴드의 비밀: 왜 고차원에서 저차원이 나올까?
학생이 좋은 질문을 했다: "이미지 데이터는 매끄러운 가정이 직관적인데, 키와 몸무게 같은 데이터는 어떻게 이해해야 하나요?"
키-몸무게 예시
2차원 데이터(키, 몸무게)를 생각해보자. 샘플들이 어떻게 분포할까?
몸무게
↑
| ●●●●●●●
| ● ●
| ● ●
| ● ●
|●____________●→ 키
선형적인 관계를 보인다. 키가 크면 몸무게도 무겁다 (일반적으로). 이 선형 관계가 1차원 매니폴드다.
매니폴드 상에서:
- X축 방향 이동: 키와 몸무게가 함께 증가
- 급격한 점프 없음: 키 170cm에서 갑자기 110cm로 점프하지 않음
- 매끄러운 변화: 인접한 샘플끼리 조금씩만 다름
이 1차원 매니폴드를 펼치면 0~1 사이의 수직선이 된다. 2차원 정보를 1차원으로 압축하되, 본질적인 관계는 보존하는 것이다.
MNIST 예시
784차원의 MNIST는 어떨까?
전체 784차원 공간은 거대하다. 하지만 실제 숫자 이미지가 존재할 수 있는 영역은 그중 극히 일부다. 이 영역이 매니폴드다.
예를 들어 숫자 '1'의 매니폴드:
- Z₁축: 크기 (작은 1 → 큰 1)
- Z₂축: 각도 (0도 → 5도 → 10도 → 45도)
- Z₃축: 위치 (왼쪽 → 중앙 → 오른쪽)
이 3차원 매니폴드에서 샘플링하면 다양한 '1'이 생성된다. 784차원 정보를 3차원으로 표현하되, '1'다운 모든 변화를 포착하는 것이다.
왜 이것이 가능한가?
중복과 상관관계 때문이다.
784개 픽셀이 각각 독립적이라면 진짜 784차원이 필요하다. 하지만 그렇지 않다:
- 한 픽셀이 켜지면 인접 픽셀도 켤 가능성이 높다 (선이 이어지므로)
- 왼쪽 위가 밝으면 오른쪽 아래도 특정 패턴을 보인다 (숫자 모양이므로)
- 특정 픽셀 조합은 절대 나타나지 않는다 (의미 없는 노이즈)
이 엄청난 상관관계와 제약 때문에, 실제 자유도는 훨씬 작다. 이것이 고차원 데이터가 저차원 매니폴드에 사는 이유다.
매끄러운 가정의 의미
매끄러운 가정은 매니폴드 위에서의 여행이 부드럽다는 것이다.
숫자 이미지 매니폴드에서:
- X축을 따라 천천히 이동하면: 1의 크기가 서서히 커진다
- Y축을 따라 천천히 이동하면: 1이 서서히 기울어진다
- 갑작스러운 점프 없음: 1이 갑자기 7로 바뀌지 않는다
이 매끄러움이 왜 중요할까?
보간(interpolation)이 가능해진다. 두 샘플 사이의 중간 지점을 생성하면, 의미 있는 새 샘플이 만들어진다. 작은 1과 큰 1 사이를 보간하면 중간 크기의 1이 나온다.
일반화가 가능해진다. 트레이닝 샘플 근처의 테스트 샘플은 비슷한 특성을 가질 것이다. 매니폴드가 매끄럽게 변하므로.
에필로그: 레이블 없는 세계의 풍요로움
비지도학습은 처음엔 제약처럼 보인다. 레이블이 없다니, 뭘 할 수 있을까?
하지만 오히려 그 제약이 창의성을 낳는다. 레이블 없이도 할 수 있는 일이 이렇게 많다:
- 유사한 것들을 묶고 (군집화)
- 새로운 것을 만들고 (생성 모델)
- 본질을 추출하고 (차원 축소)
- 패턴을 발견한다 (밀도 추정)
유튜브가 당신을 이해하는 것도, 넷플릭스가 영화를 추천하는 것도, 스팸 필터가 이상한 이메일을 찾아내는 것도 모두 비지도학습의 산물이다.
레이블이라는 명시적 지도 없이도, 데이터의 내재된 구조를 발견하고 활용한다. 매니폴드와 매끄러움이라는 사전 지식을 무기로, 고차원의 혼돈에서 저차원의 질서를 찾아낸다.
그리고 K-means와 EM 같은 우아한 알고리즘들이, 단순함 속에 깊은 수학적 보장을 품고, 수십 년간 우리와 함께 해왔다.
다음 시간엔 이 아이디어들이 어떻게 발전해 현대의 생성 모델로 이어지는지 살펴볼 것이다. Variational Autoencoder, GAN, 그리고 Diffusion Model까지. 비지도학습의 여정은 계속된다.
복습 질문
1. K-means에서 Expectation 단계는 무엇이고, Maximization 단계는 무엇인가?
E-step (Expectation 단계):
- 은닉 변수인 군집 중심 Z를 추정하는 단계
- 현재 각 군집에 할당된 샘플들의 평균 위치로 군집 중심을 업데이트
- 예: 파란색 군집에 속한 60개 샘플의 X좌표 평균, Y좌표 평균을 계산해 z₁ 갱신
M-step (Maximization 단계):
- 은닉 변수 Z를 이용해 각 샘플의 군집 소속 A를 결정하는 단계
- 각 샘플을 가장 가까운 군집 중심에 할당
- 목적 함수 J = Σᵢ Σₖ aᵢₖ · dist(xᵢ, zₖ)를 최소화 = likelihood를 최대화
핵심: 직접 샘플의 군집을 알 수 없으므로, 군집 중심이라는 은닉 변수를 통해 간접적으로 문제를 해결한다.
2. 왜 K-means는 iteration을 반복할수록 반드시 개선되거나 동일한 성능을 보장하는가?
수학적 보장의 원리:
목적 함수 J는 두 변수에 의존한다:
- A (샘플의 군집 소속)
- Z (군집 중심 위치)
E-step에서: Z가 고정되어 있을 때
- 각 샘플을 가장 가까운 중심에 할당하면 J가 최소화됨
- 또는 J가 동일하게 유지됨 (이미 최적 할당이었다면)
- 절대 J가 증가하지 않음
M-step에서: A가 고정되어 있을 때
- 각 군집의 샘플 평균으로 중심을 이동하면 J가 최소화됨
- 또는 J가 동일하게 유지됨 (이미 최적 위치였다면)
- 절대 J가 증가하지 않음
결론: 두 단계를 번갈아 수행하면
- J(t+1) ≤ J(t) 가 항상 성립
- Likelihood의 lower bound가 단조증가
- 따라서 iteration을 더 돌려서 성능이 나빠지는 일은 수학적으로 불가능
시각적 증거: K-means 애니메이션을 보면 샘플들이 점점 군집 중심으로 빨려들어가는 것을 볼 수 있다. 이것은 "우연히 그렇게 보이는 것"이 아니라 수학적으로 보장된 현상이다.
3. Mahalanobis distance가 유클리디안 distance와 다른 점은 무엇이며, 언제 유용한가?
유클리디안 distance (L² norm):
d_Euclidean = √[(x₁-y₁)² + (x₂-y₂)²]
- 물리적 거리만 측정
- 분포의 형태를 고려하지 않음
- 모든 방향이 동등하게 취급됨
Mahalanobis distance:
d_Mahalanobis = (x - μ) / σ
또는 다변량 형태:
d² = (x - μ)ᵀ Σ⁻¹ (x - μ)
- 통계적 거리를 측정
- 분포의 형태(표준편차, 공분산)를 고려
- 방향에 따라 다른 스케일 적용
핵심 차이점 예시:
두 군집이 있다고 하자:
군집 A (표준편차 작음): ●●●●● x₁
군집 B (표준편차 큼): ● ● ● ● ● x₂
평균에서 x₁까지와 평균에서 x₂까지의 물리적 거리가 동일해도:
- 유클리디안: 두 거리를 동일하게 취급
- Mahalanobis:
- x₁은 통계적으로 매우 먼 outlier (표준편차가 작으므로)
- x₂는 통계적으로 가까운 정상 샘플 (표준편차가 크므로)
언제 유용한가?
- Outlier 탐지: 물리적으로 가까워도 통계적으로 이상한 샘플을 찾을 때
- 비등방성 분포: 데이터가 타원형으로 퍼져있을 때
- 상관관계 고려: 특징들 간 상관관계를 거리에 반영해야 할 때
- Likelihood 계산: 가우시안 분포 가정 하에서 확률적 군집화를 할 때
Mahalanobis distance를 K-means에 사용하면 outlier에 더 강건한 군집화가 가능하다.
4. 매니폴드 가정과 매끄러운 가정의 차이는 무엇이며, 둘이 함께 작동하면 어떤 일이 가능해지는가?
매니폴드 가정 (Manifold Hypothesis):
정의: 고차원 특징 공간에서 데이터는 특정한 **저차원 구조(매니폴드)**에 집중되어 있다.
의미:
- MNIST는 784차원 공간에 살지만
- 실제로는 훨씬 낮은 차원(예: 10~20차원)의 매니폴드에 분포
- 전체 공간이 아닌 특정 부분공간만 의미 있음
비유:
- 서울(784차원)은 거대하지만
- 사람들은 주로 지하철 노선(저차원 매니폴드)을 따라 움직인다
- 전체 도시를 알 필요 없이 지하철 노선만 알면 대부분 설명 가능
왜 가능한가?:
- 픽셀들이 독립적이지 않고 강한 상관관계를 가짐
- 의미 없는 노이즈 패턴은 제외됨
- 실제 자유도는 명목 차원보다 훨씬 작음
매끄러운 가정 (Smoothness Assumption):
정의: 매니폴드 위에서 이동할 때, 샘플의 특성이 부드럽게 연속적으로 변화한다.
의미:
- 매니폴드의 X축 방향: 숫자 크기가 점진적으로 변화
- 매니폴드의 Y축 방향: 회전 각도가 연속적으로 변화
- 갑작스러운 점프 없음: 1이 갑자기 7로 바뀌지 않음
수학적 표현:
- 인접한 두 점 x₁, x₂에 대해
- d(x₁, x₂)가 작으면 → f(x₁)과 f(x₂)도 유사
- 리프쉬츠 연속성 또는 매끄러운 함수 가정
키-몸무게 예시:
- 키 170cm에서 175cm로 이동하면
- 몸무게도 점진적으로 증가 (갑자기 2배 되지 않음)
- 매니폴드를 따라 부드러운 곡선
둘이 함께 작동하면?
1. 효율적인 표현 학습
- 매니폴드 가정: 784차원 → 10차원으로 압축 가능함을 보장
- 매끄러운 가정: 10차원 공간에서의 구조가 의미 있음을 보장
- 결과: Autoencoder 같은 차원 축소가 작동하는 이유
2. 일반화 능력
- 매니폴드 가정: 트레이닝과 테스트 샘플이 같은 매니폴드에 있음
- 매끄러운 가정: 트레이닝 샘플 근처의 테스트 샘플은 유사한 특성
- 결과: 적은 데이터로도 일반화 가능
3. 보간과 생성
- 매니폴드 가정: 의미 있는 샘플들이 모여있는 공간 정의
- 매끄러운 가정: 두 샘플 사이를 보간하면 의미 있는 중간 샘플 생성
- 결과:
- 작은 고양이와 큰 고양이 사이 보간 → 중간 크기 고양이
- 0도 회전과 45도 회전 사이 보간 → 20도 회전된 이미지
4. 군집화와 분류
- 매니폴드 가정: 유사한 샘플들이 매니폴드의 같은 영역에 모임
- 매끄러운 가정: 경계가 명확하게 구분됨 (불연속 점프 없이)
- 결과: K-means 같은 알고리즘이 의미 있는 군집 발견
5. 준지도학습
- 매니폴드 가정: 레이블 없는 데이터도 같은 구조에 분포
- 매끄러운 가정: 레이블된 샘플 근처는 같은 레이블일 확률 높음
- 결과: 소수 레이블로 전체 구조 학습 가능
실용적 의미:
이 두 가정이 없다면:
- 차원의 저주에 갇힘 (784차원 전체를 탐색해야 함)
- 일반화 불가능 (테스트 샘플이 트레이닝 영역 밖일 수 있음)
- 보간 무의미 (중간값이 말이 안 됨)
이 두 가정이 있기에:
- 고차원 → 저차원 압축 가능
- 적은 샘플로 일반화 가능
- 새로운 샘플 생성 가능
- 비지도학습 자체가 의미를 가짐
결론: 매니폴드 가정은 "어디에 데이터가 있는가"를, 매끄러운 가정은 "그곳에서 어떻게 변하는가"를 말한다. 둘이 결합되면 레이블 없이도 데이터의 내재된 구조를 발견하고 활용할 수 있게 된다. 이것이 비지도학습이 작동하는 근본 원리다.