Attention의 혁명: Sequence-to-Sequence에서 Transformer까지
프롤로그: RNN의 다음 단계
우리는 RNN과 LSTM을 배웠습니다. 순환 엣지 하나로 시간성을 다루고, 메모리와 게이팅으로 장기 의존성 문제를 해결했죠.
그 다음에 나온 게 Sequence-to-Sequence 모델입니다.
Sequence-to-sequence, 이름에서 알 수 있듯이 입력도 sequence고 출력도 sequence입니다. Sequence라는 말은 순서가 있는 단어들의 집합을 의미합니다.
어디에 쓰일까요?
- 한국어 → 영어 번역
- 문장 생성
- Chatbot
- Summarization (요약)
- Speech to Text (음성 인식)
Sequence-to-Sequence의 구조
인코더와 디코더
구조는 간단합니다: **인코더(Encoder)**와 디코더(Decoder) 두 부분으로 구성됩니다.
입력: "I am a student"
↓ 인코더
Context Vector (컨텍스트 벡터)
↓ 디코더
출력: "Je suis étudiant" (프랑스어)
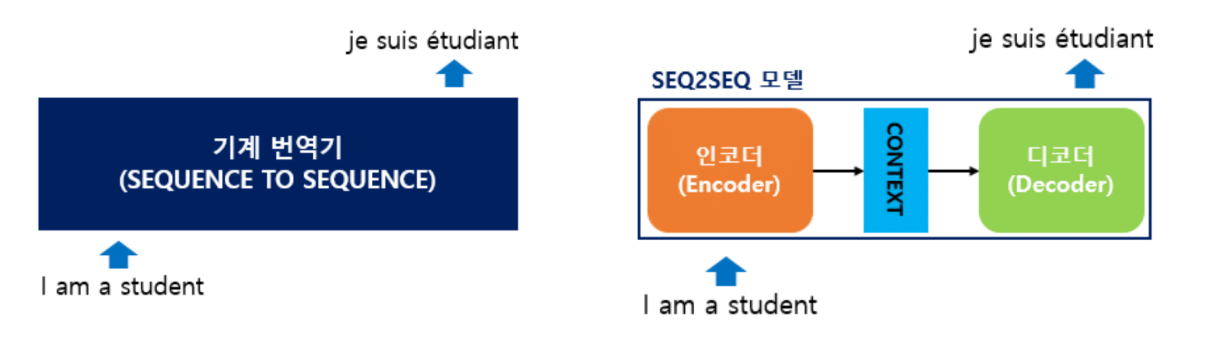
인코더의 역할
입력 문장의 모든 단어들을 순차적으로 입력받은 다음, 그걸 가지고 하나의 context vector를 만들어냅니다.
Context vector 안에는 앞에서 순차적으로 들어갔던 모든 단어에 대한 정보가 레이턴트(latent, 은닉)의 형태로 들어있습니다.
쉽게 말하면 인코더의 출력 = 레이턴트 벡터라고 보시면 됩니다.
디코더의 역할
디코더는 어떤 걸 하느냐?
인코더에서 받은 context vector와 새로운 단어를 입력받아서 다음에 나올 단어를 출력합니다.
Context + <START> → "Je" (제)
Context + "Je" → "suis" (스위)
Context + "suis" → "étudiant" (에티당)
Context + "étudiant" → <END>
특징: 그 다음 입력은 이전 출력을 그대로 입력으로 씁니다.
Special Tokens
두 가지 특수 문자가 있습니다:
SOS (Start of Sequence)
- 디코더에 가장 처음 들어가는 문자
- Sequence의 시작을 알려줌
EOS (End of Sequence)
- Sequence의 끝을 알려줌
- 이 토큰이 나올 때까지 디코더는 반복적으로 단어 생성
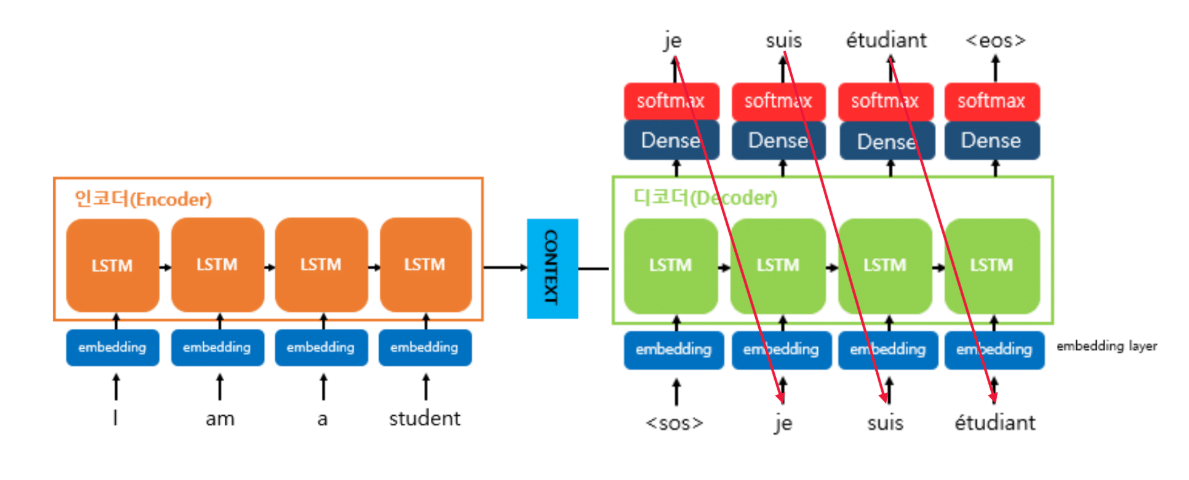
Teacher Forcing: 학습의 비밀
학습할 때 어떻게 레이블을 만들까요?
입력 X: "I am a student"
출력 Y: "Je suis étudiant"
이걸 가지고 어떻게 레이블을 만드나요?
간단합니다!
맨 앞에 <SOS>를 붙이고, 끝에 <EOS>를 붙이면:
디코더 입력: <SOS> Je suis étudiant
디코더 출력: Je suis étudiant <EOS>
- <SOS> 입력 → "Je" 출력
- "Je" 입력 → "suis" 출력
- "suis" 입력 → "étudiant" 출력
- "étudiant" 입력 → <EOS> 출력
한 문장만 있으면 모든 시점에서의 타겟 값을 만들어낼 수 있습니다. 디코더에서는 입력과 출력에 대한 명백한 데이터가 존재하는 거죠.
이렇게 하나의 문장을 가지고 <SOS>와 <EOS>를 넣어서 학습 데이터를 손쉽게 만드는 걸 Teacher Forcing이라고 부릅니다.
Sequence-to-Sequence의 치명적 문제
Context Vector의 한계
아무리 LSTM으로 메모리를 만들고 게이팅으로 선택적 저장을 해도, 여전히 문제가 있습니다.
문장이 엄청나게 길어지면 길어질수록, context vector는 제한되어 있습니다.
예를 들어 512차원이라고 합시다. 이 작은 차원 안에 문장 안의 모든 정보를 다 집어넣어야 합니다.
결과적으로 특정 정보들이 희석될 가능성이 높습니다.
"I am a student"에서 "I"는 희석되고 "student"에 대한 정보만 가득 들어있을 수도 있어요.
정보 희석의 필연성
Sequence-to-Sequence 모델의 근본적 문제:
인코더에서 모든 단어를 한 방에 다 받아서 context vector에 쑤셔 넣은 다음, 그걸 가지고 디코딩을 시작하는 구조입니다.
정보 희석 가능성이 높습니다.
특히 장기 문맥이 길어지면 길어질수록 희석되는 정보가 더 많아집니다.
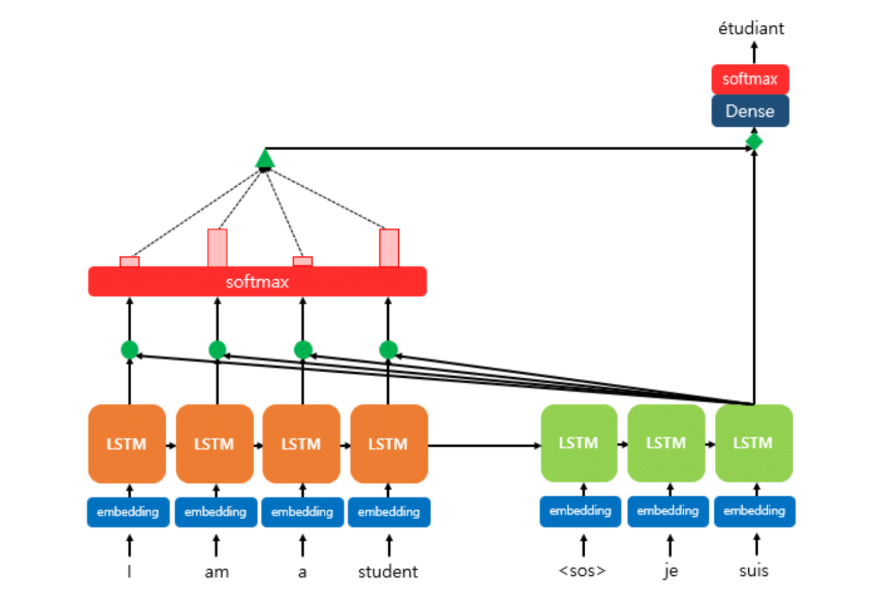
Attention의 등장
이 문제를 해결하기 위해 나온 아이디어가 바로 Attention입니다!
핵심 아이디어
Attention은 디코더 단에서 발생합니다.
디코더에서 출력 단어를 예측하는 매 시점마다 인코더의 전체 문장을 참고하는 겁니다.
Context vector도 물론 사용되지만, 어쨌든 내가 예를 들어 "suis"라는 단어를 입력으로 넣어서 다음 단어가 뭔지 예측할 때, 인코더에 있는 "I am a student" 각각의 단어를 다 고려해서 출력값을 낸다는 겁니다.
그렇게 하면 context vector가 가지고 있는 제한된 용량, 희석 문제를 엄청나게 완화할 수 있습니다.
Pay Attention!
Attention, "pay attention"이라는 말은 특정한 어떤 사물에 집중한다는 의미입니다.
집중의 핵심은 뭐냐?
모든 입력 문장을 다 동일한 비율로 참고하는 게 아니라, 해당 시점에서 예측해야 할 단어와 연관(relation)이 있는 부분을 집중해서 참고하는 겁니다.
예를 들어:
"Je suis étudiant"를 생성할 때
"Je" → "I"와 관련 (높은 가중치)
"suis" → "am"과 관련
"étudiant" → "student"와 관련
이 단어를 디코딩할 때는 연관 있는 단어에 집중해서 그 단어의 정보를 최대한 활용하고, 나머지 단어들은 좀 덜 가중치를 주어 반영합니다.
이게 바로 연관성을 이용한 Attention Mechanism입니다.
Attention의 메커니즘: Dictionary에서 배우다
Dictionary 자료형
Attention 함수는 Dictionary 자료형에서 착안되었습니다.
Dictionary는 키(Key)와 값(Value)의 매핑 관계로 이루어져 있죠.
Dictionary = {
2017: "Transformer",
2018: "BERT",
2019: "GPT-2"
}
키를 넣으면 값이 나옵니다. 2017을 집어넣으면 "Transformer"가 나오는 식입니다.
Dictionary는 1대1 매핑입니다. 하나를 넣으면 딱 하나가 나옵니다.
Soft Dictionary: Attention의 본질
Attention Mechanism은 이 Dictionary를 "소프트"하게 만들었습니다.
어떻게?
쿼리(Query)와 키의 유사도를 기반으로 가중치화된 값을 반환합니다.
무슨 말이냐?
- 쿼리를 던집니다 (내가 찾고 싶은 정보)
- 쿼리와 키들 간의 유사도를 비교합니다
- 가장 유사도가 높은 키 → 높은 가중치 (예: 0.8)
- 유사도가 낮은 키 → 낮은 가중치 (예: 0.1)
- 각 값(Value)에 가중치를 곱해서 더합니다
Value_final = 0.1×Value₁ + 0.8×Value₂ + 0.1×Value₃
Dictionary vs Attention
공통점:
- 쿼리를 날림
- 키와 비교
- 값을 도출
차이점:
- Dictionary: 하나의 값만 도출
- Attention: 소프트한 값 도출 (유사도 기반 가중 합)
유사도가 높으면 높은 가중치, 낮으면 낮은 가중치로 값들을 **weighted sum(가중 합)**해서 값을 도출합니다.
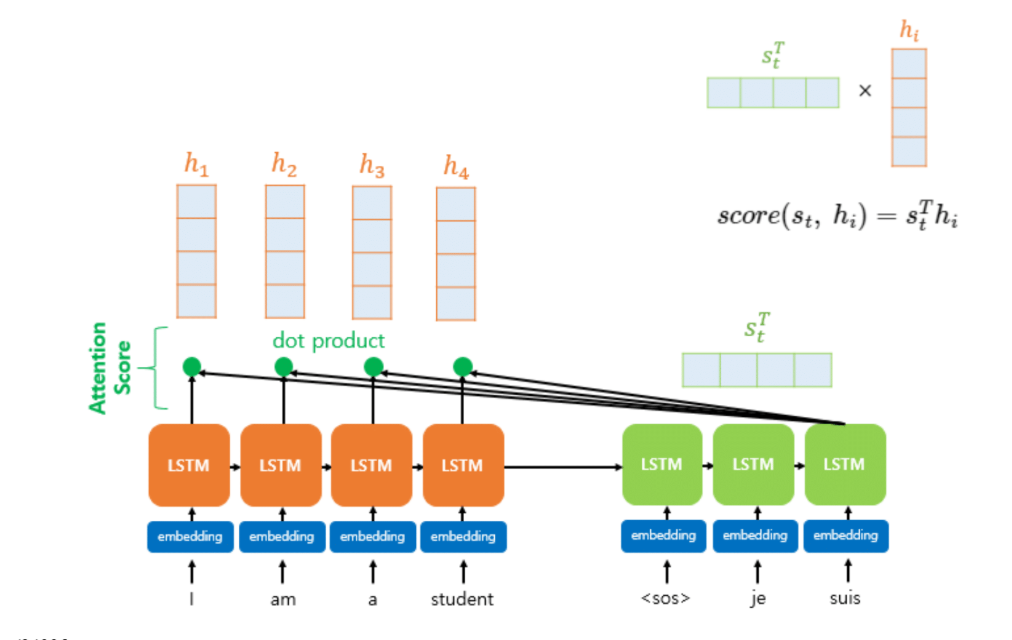
Dot Product Attention
구체적 작동 방식
디코더에 "suis"라는 단어가 들어왔다고 합시다.
디코더: "suis" 벡터 (임베딩)
인코더: ["I", "am", "a", "student"] 각각의 벡터
1단계: 내적(Dot Product)
"suis" 벡터와 인코더의 각 단어 벡터를 내적합니다.
내적한다는 말의 의미: 가장 비슷한 임베딩이 뭔지를 찾는 겁니다.
내적 값이 크다 = 두 벡터가 Vector space에서 같은 방향 = 유사도(similarity)가 높다
"suis" · "I" = 10
"suis" · "am" = 50
"suis" · "a" = 1
"suis" · "student" = 5
2단계: Softmax
Softmax([10, 50, 1, 5])
→ [0.05, 0.8, 0.05, 0.1]
가장 많이 attention되는 단어가 뭔지 알 수 있습니다.
Attention이 많이 된다 = 이 단어와 가장 임베딩 관점에서 유사한 단어
3단계: Weighted Sum
Softmax를 통과한 값들을 각 h(은닉 벡터)에 곱해서 더합니다:
Attention_value = 0.05×h_I + 0.8×h_am + 0.05×h_a + 0.1×h_student
이게 Dot Product Attention입니다!

Key와 Value의 이중 역할
여기서 중요한 점:
H가 Key로도 존재하고 Value로도 존재합니다.
- Query: 디코더의 "suis"
- Key: 인코더의 각 h (유사도 비교용)
- Value: 인코더의 각 h (가중 합 계산용)
같은 h가 두 가지 역할을 동시에 합니다.
Context Vector의 한계 극복
이렇게 하면 인코더의 어떤 단어든지 attention이 잘 되면 활용이 되는 겁니다.
Context vector 안에 그 정보가 잘 못 들어간 단어가 있을지라도, 문제없이 인코더에 있는 단어들이 잘 사용됩니다.
최종 단계: Concatenation
Attention value를 얻었으면, 원래 내가 입력한 "suis"라는 임베딩과 **다시 연결(concatenate)**합니다.
"suis" 임베딩: 4차원
Attention value: 4차원
→ Concat: 8차원
이 8차원을 최종적으로 출력층의 입력으로 사용합니다.
앞에 있는 모든 인코더 단어들이 다 사용되기 때문에, Sequence-to-Sequence가 가지고 있던 희석 문제가 상당히 많이 완화됩니다.

Softmax의 한계
하나만 집중할 수 있다
한 학생이 날카로운 질문을 했습니다:
"문장의 길이가 길면 결국 softmax를 통과하니까 여러 개를 집중해야 하는데, 그중 한 단어만 집중하는 게 문제 아닌가요?"
정확합니다! Softmax가 가지고 있는 한계죠.
예를 들어:
"나는 철수입니다. 나는 어쩌고저쩌고... 그는 ..."
"그"가 "철수"도 될 수 있고 "나"도 될 수 있습니다. 둘 다 attention해야 하는데, Softmax는 하나만 선택합니다.
나만 attention 되거나 철수만 attention됩니다. 나와 철수가 같이 attention 되는 게 더 좋아 보이는데, 그게 안 됩니다.
-> softmax는 어차피 가중합하는거라 모든 단어를 고려함. 해당 질문은 softmax 특성상 하나의 가중치가 너무 커서 다른 정보가 희석되는 문제에 대한 것이라 생각해야할 듯. 그러면 말이됨. 이 경우 여러 관점에서 문장을 해석하도록 multi-head attention을 두면 됨
해결책: Multi-Head Attention
이 문제를 어떻게 극복했을까요?
Transformer에서는 어떻게 했을까요?
답: Multi-Head Attention
인코더를 한 개만 쓰는 게 아니라 여러 개 씁니다.
- 첫 번째 head: "나"를 attention
- 두 번째 head: "철수"를 attention
각각의 인코더가 조금 다른 viewpoint를 가지고 있는 겁니다.
양으로 모든 걸 극복한다!
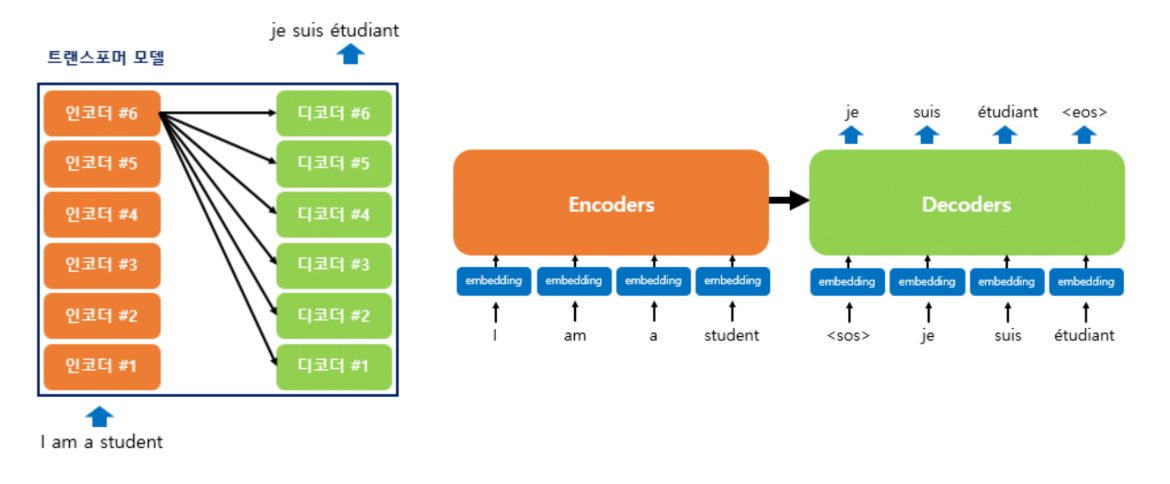
Transformer의 탄생
Attention is All You Need
사람들이 Attention을 써보니까 깜짝 놀랐습니다. 너무 잘 되는 거예요.
"와, Attention이라는 게 진짜 물건이다!"
Attention을 더 고도화하자. 그래서 나온 것이 Transformer입니다.
논문 제목: "Attention is All You Need"
당신이 필요한 건 Attention밖에 없다.
Attention만 있으면 됩니다. 딴 거 필요 없어요. 여러 가지 복잡한 거 붙이지 말고, 진짜 Attention에 집중해서 Attention을 제대로 구현하자!
구조의 단순함
실제로 Transformer는 Attention 블록을 제외하면:
- Fully Connected Layer 2개
- Normalization 블록 (원래 있던 거)
이게 전부입니다.
Attention으로만 구성된 모델이 Transformer라고 할 수 있습니다.
이때 Attention을 더 정교하게 만들었어요. 그게 Transformer의 특징입니다.
Transformer의 핵심 Parameters
D_model: 임베딩 차원
입력 벡터, 임베딩되는 벡터의 크기입니다.
원핫 벡터: [0,0,1,0,0,...] (3천 차원)
↓ 임베딩
임베딩 벡터: [...] (512차원)
이 512차원이 바로 D_model입니다.
중요: 이 512차원은 처음부터 끝까지 계속 동일하게 유지됩니다. 한 단어, 한 토큰이 가지고 있는 차원의 길이는 중간에 변하지 않습니다.
각각의 차원은 채널로 볼 수 있습니다. 첫 번째 채널, 두 번째 채널... 각각 고유한 채널로 동작합니다.
512개의 채널을 사용한다. 차원은 항상 유지된다. 모든 곳에서.
Num_layer: Attention Block 개수
Attention block을 몇 개 쌓았느냐? 6개 쌓았습니다.
인코더 디코더가 각각 6개씩 쌓였다는 의미입니다.
Num_head: Head 개수
인코더의 개수가 몇 개냐? 특히 Attention 블록 내부적으로 독립적으로 attention을 수행하는 모듈이 몇 개냐?
하나의 head는 하나의 attention을 독립적으로 수행합니다.
8개면 8개가 서로 다른 attention을 수행해서:
- 첫 번째 head: 예를 들어 "철수"를 attention
- 두 번째 head: "나"를 attention
여러 관점에서의 attention을 수행할 수 있습니다.
D_ff: Fully Connected Layer
내부 은닉층의 노드 개수: 2048
2048개의 은닉 노드가 있고, 다시 512차원으로 매핑합니다.
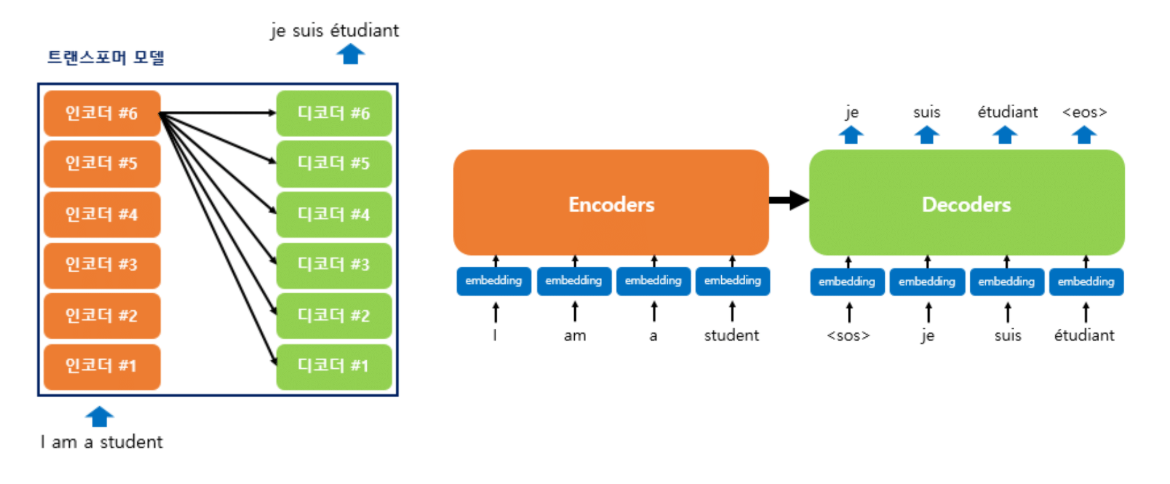
Transformer의 특징 1: Multi-Head Attention
구조
Multi-head는 쉽게 말하면 인코더가 여러 개 있는 것과 같습니다.
마찬가지로 Decoder도 여러 개 있는 것과 동일한 구조를 가집니다.
작동 방식
입력 벡터 길이가 16이라고 합시다. Head 개수가 8개면?
Q, K, V 가중치 매트릭스의 출력 차원을 2로 만듭니다.
- 첫 번째 head: 2차원 출력
- 두 번째 head: 2차원 출력
- ...
- 여덟 번째 head: 2차원 출력
→ 2차원 × 8개 = 16차원으로 다시 복원!
입력 크기와 출력 크기가 동일합니다.
앙상블 효과
서로 조금씩 다른 관점으로 학습된 모델들을 합쳐서 하나의 출력물을 만든다고 생각하면 됩니다.
앙상블(Ensemble)의 효과가 있습니다. 풍부한 context 정보를 획득할 수 있죠.
Transformer의 특징 2: Positional Encoding
왜 필요한가?
LSTM에서는 각 단어가 어느 위치에 있는지 알려줄 필요가 전혀 없었습니다. 항상 순서대로 들어갔으니까요.
가장 마지막 단어들은 가장 많이 사용됐겠죠 (곱셈으로). 위치 정보가 자연스럽게 반영되었습니다.
Transformer로 넘어오면서: 인코더의 단어가 한 방에 다 들어갑니다.
순차적으로 들어가는 게 아니라 "I am a student"가 한 번에 다 들어가기 때문에:
- "I"가 첫 번째 위치인지
- "am"이 두 번째 위치인지
위치 정보를 명시적으로 알려줄 필요가 있습니다.
디코더도 마찬가지입니다.
가장 단순한 방법의 문제
가장 쉽게 생각할 수 있는 방법:
첫 번째 위치: [1, 1, 1, 1, ...]
두 번째 위치: [2, 2, 2, 2, ...]
세 번째 위치: [3, 3, 3, 3, ...]
명확하죠? 각 position마다 숫자를 주는 겁니다.
그런데 이 방식을 쓰지 않습니다. 왜일까요?
값 폭발의 위험
한 학생이 정확히 지적했습니다:
"문장이 길어지면 큰 값이 더해져서 문제가 되지 않나요?"
맞습니다!
하나의 sequence에 천 개의 단어가 들어있다면?
마지막 단어는 각 element에 천이 더해집니다.
1을 더한 것 vs 1000을 더한 것
→ 1000배 스케일 차이!
천이라는 큰 값이 네트워크 안에 들어가서 값이 폭발할 수 있습니다.
단순하게 1, 2, 3, 4를 더해주는 건 포지션을 정한다는 관점에서는 말이 되지만, 네트워크가 폭발할 위험이 있는 거죠.

해결책: Sin & Cosine
Positional Encoding에서는 네트워크 폭발 가능성이 없는 함수인 sin과 cosine 함수를 도입했습니다.
특징:
- 주기 함수
- 마이너스 1에서 1 사이의 안정된 범위
sin과 cosine 함수를 번갈아 가면서:
- 짝수 차원: sin 함수
- 홀수 차원: cosine 함수
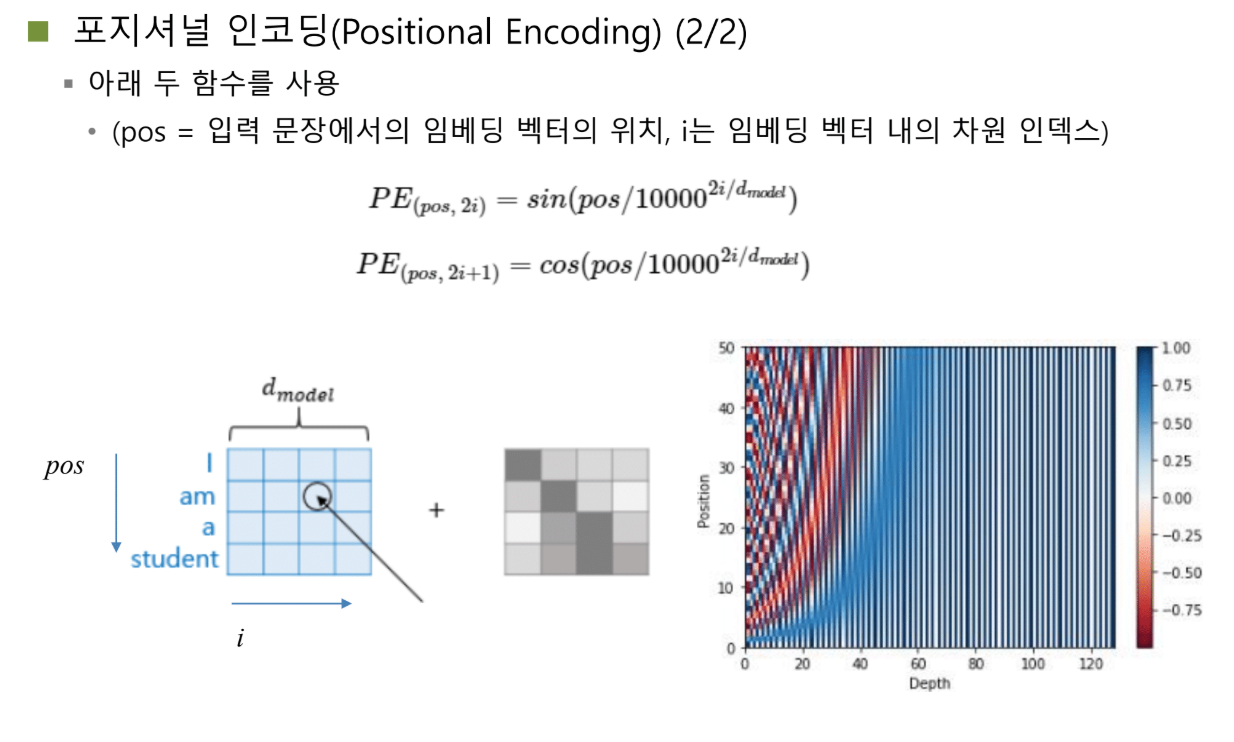
두 가지 효과
1) 고유한 패턴
모든 토큰마다 자신의 위치에 대한 고유한 패턴을 positional embedding으로 받습니다.
중요: "고유하다" - 두 개가 다 index 1이면 순서가 헷갈립니다. 순서가 전혀 헷갈리지 않도록 모든 positional encoding vector는 다 다른 모양을 가집니다.
2) 값 폭발 방지
sin과 cosine은 마이너스 1에서 1 사이를 왔다 갔다 하는 함수이기 때문에, 전체 값을 크게 바꾸지 않으면서도 위치가 어딘지를 적절하게 줄 수 있습니다.
현대의 발전
지금은 상대적인 거리를 계산해서 사용합니다. 그게 더 성능이 좋답니다.
- Position: 단어의 index (첫 번째, 두 번째, ...)
- Depth: 한 단어가 가지고 있는 채널의 길이 (벡터의 길이)
이런 정보를 원래 단어에 더해서 인코더에 입력으로 집어넣습니다.
Transformer의 Attention: 세 가지 종류
Transformer는 Attention을 좀 세분화해서 세 가지 종류의 attention을 만들었습니다.

1. Self-Attention (인코더)
인코더에서 동작하는 attention입니다.
자기 자신을 가지고 Q, K, V를 다 만들어서, 입력되는 prompt 안에서 attention을 수행합니다.
왜 필요한가?
예를 들어:
"The animal didn't cross the street because it was too tired"
"it"과 "the animal"이 서로 관련이 있죠? "The animal"이 "it"입니다.
인코더에 들어가는 prompt 안에도 유사한 attention 관계를 가질 수 있는 단어들이 당연히 존재합니다.
여러분도 prompt 입력할 때:
"나는 ... 나는 ..."
"누구누구는 ... 그 사람은 ..."
같은 사람인데 지칭을 다르게 하잖아요.
하나의 인코더 안에 들어있는 prompt 안에도 self-attention이 충분히 발생할 수 있습니다.
2. Masked Self-Attention (디코더)
디코더에서만 있는 attention 구조입니다.
사실 이 둘은 동일하지만 "masked"라는 단어가 붙었냐 안 붙었냐의 차이입니다.
Masked의 의미
Attention을 할 때 특정 단어는 attention에 포함시키지 않겠다는 말입니다. Masking을 하겠다.
왜? 디코더는 첫 번째 단어부터 순차적으로 생산해내거든요.
<SOS> 입력: <SOS>만 attention 가능 (자기 자신밖에 없음)
"Je" 입력: <SOS>와 "Je" attention 가능
"suis" 입력: <SOS>, "Je", "suis" attention 가능
그런데 미래에 나올 단어에 대해서는 attention 할 수 없습니다.
"suis" 시점에서 "étudiant"은 아직 예측하지 않았으니까요.
Teacher forcing으로 데이터로는 가지고 있을지 몰라도, inference를 고려해서 미래에 예측될 단어는 비록 내가 그 단어가 뭔지 알고 있어도 attention에서 block 처리합니다.
이게 Masked Self-Attention입니다.
-> 학습시에 미래에 올 단어를 알고 학습하면 학습이 제대로 이루어지지 않기 때문에 마스킹 필요
3. Cross-Attention (인코더-디코더)
Encoder-Decoder Cross-Attention입니다.
- Query: 디코더에서 제공
- Key & Value: 인코더에서 제공
Dot Product Attention과 거의 비슷한 방식입니다.
핵심
세 가지 종류의 다른 attention이 있었지만, 그 attention이 가지고 있는 동작은 100% 동일합니다.
차이는:
- 미래 토큰을 볼 수 있냐 없냐 (self vs masked)
- Query와 Key/Value를 어디서 참조하냐 (self vs cross)
함수 자체는 완전히 동일한 방식으로 동작합니다.
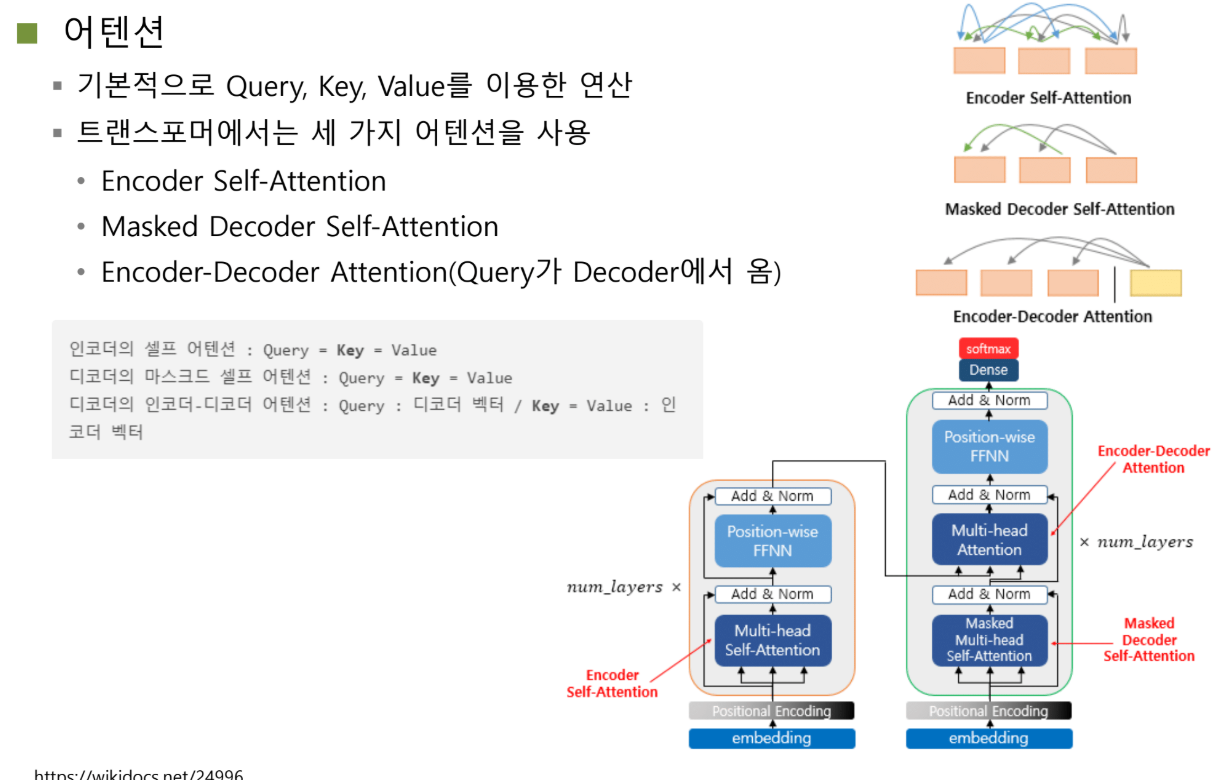
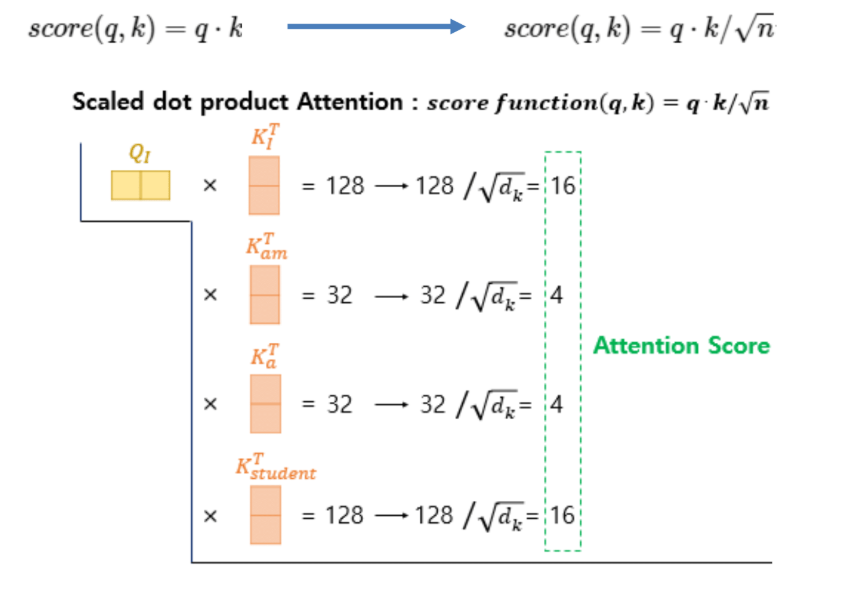
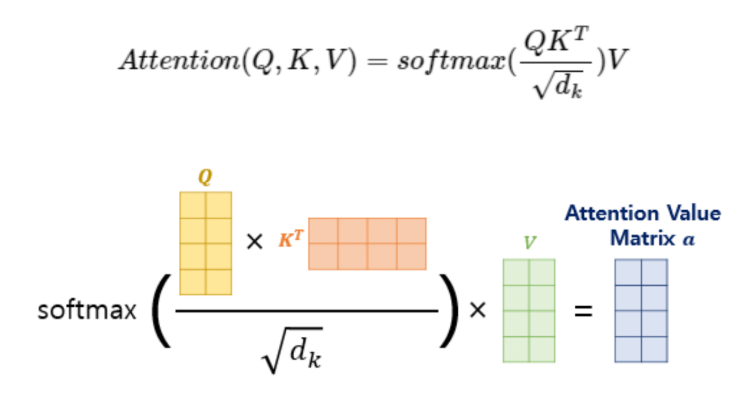
Scaled Dot-Product Attention
Dot Product Attention의 진화
원래 Dot Product Attention에서는 H를 그대로 썼습니다. H가 Value도 되고 Key도 되는 구조였죠.
Transformer는 한 단계 더 나아갔습니다.
Q, K, V의 독립적 생성
하나의 토큰이 들어가면:
X × W_q = Query
X × W_k = Key
X × W_v = Value
하나의 h를 그대로 쓰는 게 아니라, 서로 다른 선형 변환(리니어 변환) 가중치 매트릭스와의 곱을 통해, 가장 최적의 Query, Key, Value 값이 학습을 통해 결정될 수 있도록 만들었습니다.
한마디로 파라미터도 좀 더 쓰고 표현력을 높였다고 볼 수 있습니다.
Scaling: 값 폭발 방지
Q와 K를 내적하는데, 그 다음 scaling을 합니다.
벡터의 길이가 n이라면, √n만큼 나눠서 최종 attention score 값을 얻습니다.
Attention_score = (Q · K) / √n
왜 나누나?
벡터 길이가 2일 때:
(1×2) 행렬 × (2×1) 행렬
→ 출력 범위: 약 [-2, 2]
벡터 길이가 1000일 때:
(1×1000) × (1000×1)
→ 곱셈만 1000번!
→ Dynamic range: [-1000, 1000]
벡터가 길어지면 길어질수록 출력값이 굉장히 커질 수 있습니다.
특이하게 큰 값이 한 번 출력되는 순간, 그 네트워크가 엉망이 됩니다. 학습도 잘 안 되고 loss도 튀고 문제가 많이 발생합니다.
벡터 길이에 따라 √n배만큼 scaling해주는 방식이 Scaled Dot-Product입니다.

Normalization과의 유사성
우리가 normalization할 때 표준편차로 나눠주잖아요?
분산의 루트 = 표준편차
√n으로 나눠주는 게 표준편차로 나눠준다고 생각해도 무방합니다.
전체 과정
1. Q와 K 내적
2. √n으로 scaling
3. Softmax 통과
4. V와 가중 합
→ Attention Value
메커니즘은 동일합니다. 그런데 h를 그대로 쓰는 게 아니라, 가중치와 곱해서 더 좋은 표현 공간으로 보낸 다음 거기서 attention을 수행합니다.
병렬 처리의 마법
독립적 계산
입력은 X지만, Query 구할 때, Key 구할 때, Value 구할 때 서로 독립입니다.
Q 구할 때 K 신경 안 써도 되고, K 구할 때 V 아무 상관없죠.
Q, K, V를 동시에 구하는 과정은 완전히 병렬적으로 수행됩니다.
GPU가 굉장히 좋아할 만한 연산입니다!

계산 복잡도의 오해
Transformer가 계산 복잡도가 굉장히 높다고 알려져 있는데, 실제로는 그리 높지 않습니다.
요새 GPU들은 CUDA 코어가 1만 개, 2만 개씩 들어있어서, 한 방에 2만 개의 Matrix 곱을 동시에 수행할 수 있어요.
계산량이 좀 많아 보이지만, GPU 관점에서는 아무것도 아닙니다.
진짜 병목: 메모리
GPU 관점에서 Transformer의 가장 큰 **병목(bottleneck)**은:
토큰이 너무 많다!
토큰을 한 번에 쭉 불러와야 하는데, 거기서 메모리 병목이 발생합니다.
메모리가 가지고 있는 bandwidth가 제한되기 때문에, 아무리 HBM을 층층이 쌓아도 한 방에 광대역으로 토큰들을 쭉 불러올 수 있는 능력이 아직은 좀 떨어집니다.
GPU의 현재 병목은 계산이 아닙니다. 메모리입니다.
PDF 100페이지의 악몽
여러분이 PDF 전체 내용을 알고 싶어서 100페이지짜리를 넣는 순간?
Transformer는 굉장히 괴로워합니다.
PDF 100페이지 안에 얼마나 많은 단어가 들어있고, 그걸 토큰으로 환산하면 토큰이 무지하게 많습니다.
토큰이 많다 = 벡터가 어마어마하게 길다
이걸 다 불러와서 계산한다고 생각해보세요. 엄청난 계산량이 듭니다.
Feed-Forward Neural Network
단순한 MLP
Attention 모듈을 통과한 다음, Position-wise Feed Forward Neural Network를 통과합니다.
쉽게 말하면 MLP 2층짜리 쌓은 거랑 완전히 동일합니다.
입력 → Dense(2048) → ReLU → Dense(512) → 출력
첫 번째 Dense층, ReLU, 두 번째 Dense층, 출력.
왜 필요한가?
Attention은 여러 head들끼리 독립적으로 수행됐습니다. 서로 다른 viewpoint로부터 얻어진 Attention Value들을...
전체를 고려해서 더 좋은 특징 공간을 만들어낼 수 있겠죠.
전체에 대해서 correlation을 고려하기 위해 Feed Forward Neural Network 부분이 존재합니다.

Residual Connection & Layer Normalization
Residual Connection (잔차 연결)
Multi-head Attention에도 사용되고, Feed Forward에도 사용됩니다.
왜? 레이어가 깊어질수록 vanishing gradient 문제가 심각해지는데, 잔차 연결 쓰면 학습이 훨씬 더 잘 되기 때문입니다.
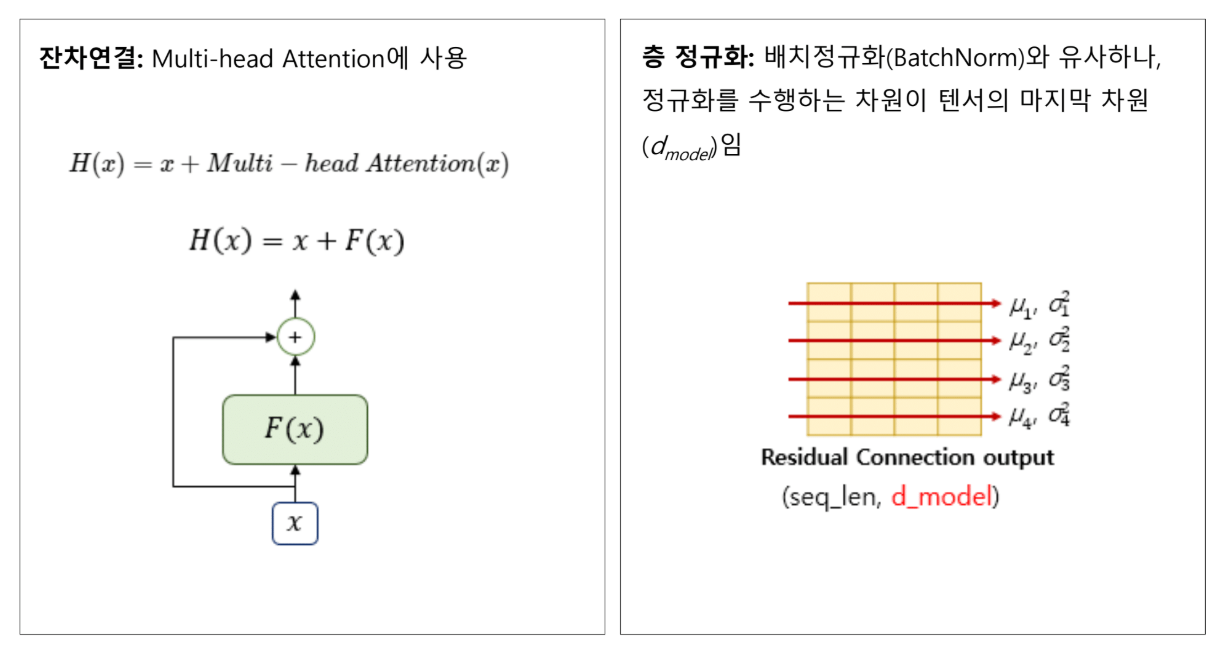
Layer Normalization
잔차 연결을 한 다음, 이 값에 대해서 normalization을 수행합니다.
Batch Normalization이 아니라 Layer Normalization입니다.
차이점
Batch Normalization: 여러 개의 입력 샘플에 대해서 normalization
Layer Normalization: 입력 샘플은 하나인데, 그 입력 샘플 안에 들어있는 각각의 토큰들에 대해서 normalization
첫 번째 토큰, 두 번째 토큰, 세 번째 토큰...
→ 채널 방향으로 평균과 분산 구함
→ Normalization 수행
왜 토큰 단위로?
특정 토큰에 값이 과도하게 몰릴 수 있습니다.
어떤 단어는 다른 단어들보다 매우 중요한 단어고, 그 단어에 너무 큰 값들이 쫙 모여 있으면?
큰 값이 모여 있다는 건 항상 문제입니다.
- Loss를 막 튀게 함
- 네트워크 안에 과도한 값이 양산
따라서 토큰 단위로 normalization을 수행합니다. 이걸 Layer Normalization이라고 부릅니다.
전체 구조의 단순함

굉장히 심플한 구조입니다!
엄청나게 심플한데, 이게 결국 굉장히 강력한 모델이 되어서 현재 AI를 주도하고 있습니다:
- ChatGPT
- Gemini
- Diffusion 모델
다 이걸 씁니다.
변화 없는 구조
이 구조에서 지금도 큰 변화가 없습니다.
여러분이 이 구조를 한 번 딱 기억하시고, 2025년에 나온 Transformer 논문을 읽으면 다 이해됩니다.
물론:
- Positional Encoding이 상대적 거리를 고려하는 방식으로 변환되거나
- Rotation을 고려해서 벡터를 회전시키는 방식으로 position을 주는 방법이 나오긴 했지만
전체적인 구조상에서는 큰 변화가 전혀 없습니다.
현대의 표준
이 구조가 현재:
- BERT
- GPT
- Vision Transformer
- Diffusion Transformer
- Large Language Models
**가장 표준 백본(backbone)**으로 사용되고 있습니다.
에필로그: Nonlinearity의 승리
MLP의 부활
맨 처음 CNN 컨볼루션 레이어가 나왔을 때, 다들 말했습니다:
"MLP는 죽었다. 너무 파라미터 많고 오버피팅만 잔뜩 발생시키고, 이제 못 쓸 것 같아."
그런데 어느새 컨볼루션 레이어가 죽고, MLP를 좀 다른 방식으로 쓰는 Attention이 다시 부활했습니다.
왜 MLP가 다시 좋아졌을까?
곰곰이 생각해보면:
Nonlinearity라는 것이 생각보다 매우 중요합니다.
Nonlinearity를 더 높일 수 있는 방식의 모델이 더 정교한 decision boundary를 만들 수 있기 때문에 더 좋은 성능을 낼 수 있습니다.
Attention = Nonlinearity의 향연
Attention model은 엄청난 nonlinearity의 향연입니다.
굉장히 nonlinear합니다:
- 리니어 변환
- Softmax 통과
- Attention 계산
- 가중 합
이 부분에서 굉장한 nonlinearity가 발생합니다.
Nonlinearity를 어떻게 더 잘 구현하느냐가 앞으로 Deep Neural Network 발전에 굉장히 중요한 요소가 아닐까 생각됩니다.
Attention은 그 정점에 있는 모델이라고 볼 수 있습니다.
요약: Sequence-to-Sequence에서 Transformer까지
Sequence-to-Sequence
- RNN/LSTM 두 개를 인코더-디코더로 묶음
- Context Vector를 인코더에서 추출해 디코더로 전달
- 문제: 장기 의존성 소실, 순차 처리 (병렬화 불가)
Attention의 등장
- 디코더 각 시점마다 인코더의 모든 단어 참조
- 유사도 기반 가중 합
- Context Vector 희석 문제 해결
Transformer
- RNN 제거 (순환 엣지 불필요)
- Self-Attention만으로 전체 모델 구성
- 장기 의존성 완전 해결
- 병렬 처리 가능
핵심 특징:
- Multi-Head Attention
- Positional Encoding (sin/cosine)
- Scaled Dot-Product Attention (√n scaling)
- Feed-Forward Neural Network (MLP 2층)
- Residual Connection + Layer Normalization